
现代控制理论 概念梳理
...
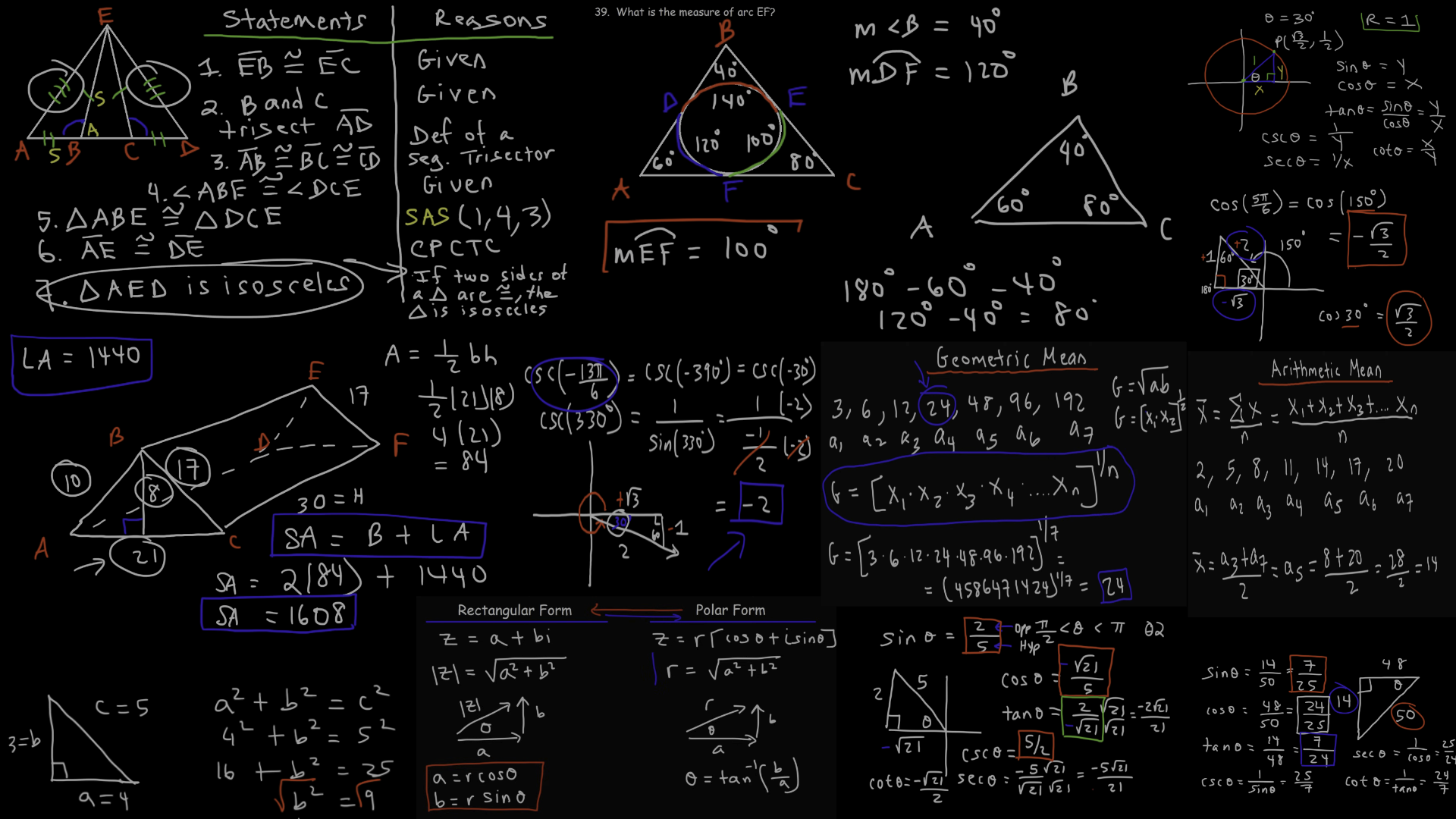
线性代数理论 伴随矩阵相关复习
前言给定系统的状态转移方程: 就可以计算对应的状态转移矩阵: 一旦有了系统的状态转移矩阵,那么我们就可以计算系统的零输入响应: 那么我们要如何计算系统的状态转移矩阵呢?时域的微分系统分析很复杂,我们可以通过拉式变换将其转换为代数系统,在代数系统求解后我们再拉式逆变换回时域。我们先将它转移到复频域(不考虑输入):然后进行一系列的代数变换,我们就可以得到零输入响应在复频域的闭合解:之后我们进行拉式逆变换就可以得到零输入响应在时域的闭合解:这个求法有两个计算点,一个是矩阵的逆的求解,另一个是拉式变换以及反变换,这篇博客讨论一下矩阵的逆为什么可以通过伴随矩阵进行求解。 数学证明从矩阵的逆的定义入手,满足下列等式的矩阵B是A的逆矩阵:这其实等价于对于B的每一列$b_j$都满足:$Ab_j=e_j$($e_j$是第j个标准基向量) 利用克拉默法则(Cramer’s Rule)...

生成式模型算法 DiT 论文解读
前言最近在看diffusion policy 的论文,感觉自己对于扩散模型的看法有些偏差。从我现在的角度来看,扩散已经不仅仅是生成式模型的实现框架,扩散可以用于任何需要建模复杂分布输出的任务。思路打开,扩散模型在我这里的重要性再上一个台阶。diffusion policy的代码实现很难读,其中有很多为了方便多任务所做的兼容性设计。所以为了完全弄懂 diffusion policy,我选择往回看,找一篇经典的里程碑式的扩散模型熟悉结构。这就是DiT。对于我来说,DiT有什么新颖的信息增益呢?我总结为下面几条:1.transformer 架构实现2.cfg 无分类器的条件引导 所以我下面就会围绕这几点来讲 transformer 架构实现扩散模型的框架我其实比较熟悉了,简单的介绍一下就是让模型能够根据噪声等级(t),加噪的图像(xt)预测...
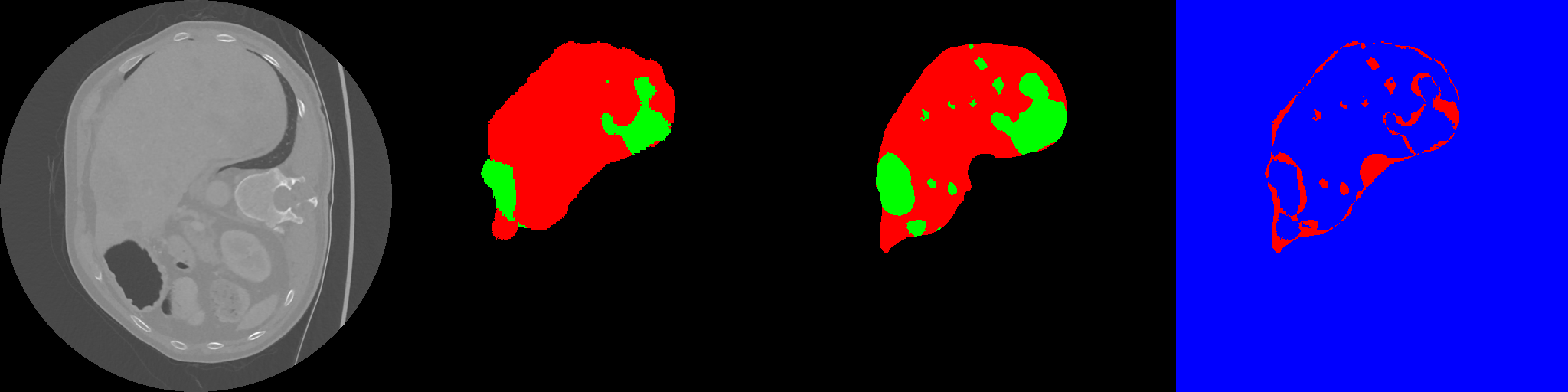
计算机视觉实践 unet lits 医学图像分割实践
前言前段时间看了很多计算机视觉的里程碑式的工作,感觉知识储备还是增加了很多的。但是因为大量的理论输入,感觉自己本就不多的实践技能由要疏忽了,所以趁着这次的课程作业的机会增加一下自己的实操经验。因为目的是增加实操经验,所以在编写代码的时候我给自己设定了几个原则:1.合理的调用深度:我曾经很喜欢cleanrl类型的一个py文件完成所有工作,并且尽量不定义函数,但是这是很不现实的,所以我给自己设定的原则是调用深度至多为一,也就是说函数之间不能嵌套(只考虑自定义函数)。并且项目不设计二级文件夹存放代码,所有代码文件都在根目录。2.尽量少的库函数调用:在代码实现过程中尽量只是用pytorch和几个基础库,避免学习成本以及可能的依赖问题。当然主要原因是为了手搓增加实战经验。 因为是实践记录并且实现内容比较初级,所以我就有选择性的进行叙述。实践仓库:abstcol/medical_image_segmentation: the medical image segmentation...

计算机视觉算法 segment anything 论文解读
前言segment anything 可以说是声名在外了,之前看遥感领域文章的时候好几篇高引文章都是结合sam完成的。 但是今天读了sam的论文后,唯一的感觉就是文章好晦涩。我思考了之后,总结出一下几个原因: sam提出了一种新的任务,为了解释这个新的任务很重要,篇幅大量往这里倾斜,其他部分的内容就少了。 新的任务肯定要新的模型,新的模型里的很多部分的组件抉择我感觉是可以大写特写的,结果只是提了一嘴用了啥,为啥用这个不用那个完全没讲。 这么多要讲的东西,论文的消融实验却消失了。整整30页的论文,消融实验只有半页。最让我难绷的是论文里关于模型偏见的部分都有一页。 其实文章没我说的那么不堪,但是也确实无法让人眼前一亮,尤其是看过depth anything的论文后。 核心观点论文作者开篇就讨论了为什么要提出一个新的模型。nlp领域的language...
计算机视觉算法 depth anything 论文解读
前言DINOV2有很多的下游应用领域,有很多工作就是将DINOV2当作预训练的backbone使用的,都取得了比较好的效果。去年我在学习遥感图像处理的时候,就用过其中的一个工作:depth anything v2(GitHub),当时只是拿来即用,没有仔细的研究过其中细节。最近正好有时间,就把这部分内容重新整理一下。(同样,对于mde领域我没有太多了解,难免有错漏之处) depth anything所用的网络架构没有什么创新,还是dpt那一套(参考我上一篇博客:计算机视觉算法 DPT(Vision Transformers for Dense Prediction)...
计算机视觉算法 depth anything v2 论文解读
前言总算学到 depth anything v2了。去年在遥感领域科研(并非科研)的时候尝试的方向就是结合深度图进行变化检测。因为只进行了简单的模型拼接效果很差,可以说是只带来了副作用。现在想来当时的具体操作上的问题暂且不谈,最大的问题是发生在宏观观念上面的。 我的目的是解决变化检测中 建筑物相关的检测正确率,假设是模型无法区别建筑物和其他后景、植物。解决方法是融合深度图作为监督增加模型对于建筑的语义理解。 开始工作前我以mde rs cd 为关键词在wos上检索了一下有没有相关工作。但是今年开学时发现mde在遥感领域有它自己的名词,而事实是深度图帮助变化检测的工作已经存在了。 对一个领域没有广泛而深入的研究之前不应该开始自己的研究。 扯得有点远了,还是说回depth anything v2吧。这篇工作的模型框架相较于depth...
计算机视觉算法 DPT(Vision Transformers for Dense Prediction) 论文解读
前言正在撰写depth anything的论文,在跑官方实现的时候发现自己在阅读论文的时候漏掉了一个满关键的组件:dpt。我觉得这个组件值得细致的学习,于是打算先完成dpt的学习以及博客撰写。先前的博客都是读完论文把东西都弄懂后按照自己理解的重要性撰写的,但是那样实在有点耗时。这一次尝试一下严格按照 abstract、intro、conclusion、related...
计算机视觉算法 DINOV2 论文解读
前言看完了DINO这篇工作,整体还是很有收获的,也是很期待DINOV2会给我带来什么惊喜。但是真的看完整篇论文才会发现其实给我带来的信息增益不是特别的多。跟我学llm时候的情况很像,想要以llama系列的技术报告为支点熟悉llm的体系框架,但是后面几个版本的技术报告内容中的部署细节很多,很难学到目前用的上的只是。DINOV2也花了一些的篇幅在部署细节上,对于这一部分我仍是味同嚼蜡。因为这一部分内容很难通过 理论学习+跟着代码执行过一遍流程 学习方法吸收。但是DINOV2和一代一样做了很多下游任务实验证明方法训练模型所抽取的特征是很好的特征,这一部分我很感兴趣,填补了我对这些下游任务实现的空白(是我见识少的缘故)。(同样,我对作者提及的其他对比算法了解十分有限,所以表述难免错漏。如有发现,欢迎在评论区指出) DINOV2训练数据论文在数据处理上花了挺多篇幅,但是我觉得结论不太能说服我。 DINOV2的数据处理分为三部分:数据获取、数据去重、数据检索。 数据获取图像数据源于网络爬取,将爬取内容中的img...
计算机视觉算法 DINO 论文解读
前言之前了解过很多的cv模型,但大多都是知道个大概。考虑到如果以后想研究具身的话,cv的前置知识是不可或缺的,于是打算把cv的里程碑式工作过一下。今天看到Emerging Properties in Self-Supervised Vision Transformers(DINO)这篇论文,觉得很有意思,写篇博客总结一下自己的看法。要注意的是,我并没有很多的cv前置知识,所以对于文中的很多技术的理解肯定是有偏差甚至错误的,希望大家宽容看待。 核心观点具体的来说,DINO是一种训练模型的宏观的方法论,对于具体应用的模型框架是没有太多的要求的。DINO的训练目标可以理解为让相似(指语义信息)的图片拥有相似的特征表示,不相似的图片拥有不相似的特征表示。 DINO是 *self-distillation with no labels* 的简称,抓住重点的话就是 self-supervised Learning(自监督)方法 和 distillation(蒸馏)...