强化学习实践 openai gymnasium D3QN算法实现 + wandb sweep超参搜索
我的Github实现:gym(GitHub)
如果想要使用模型可以直接去GitHub仓库,注释完善且规范。
觉得有用请给我点个star!
前言
最近将离散动作空间的DRL算法都实现了,也就是从DQN D2QN D3QN 的三个版本。
实事求是的讲从D2QN到D3QN所经历的改动不是太大,就是添加了一个dueling net 的网络架构,但是网络的输出仍然是Q。
所以我们只要修改Net的类定义就行了。
在实现D3QN之后,我又将模型应用到了classic control 的其他场景中,大部分都表现得很好,但是面对mountain car 却怎么都无法收敛。
在网上打算看一看其他人的超参怎么设的,却发现了这位仁兄的博客:链接。里面提到了通过对 reward 函数进行修改从而是模型收敛。之前从来没有试过对gymnasium的env进行reward进行修改,试了一下发现效果显著。
在这之后其实应该去接着学习连续动作空间的模型的,但是打算先试一试wandb的sweep功能,做一下超参搜索玩玩,确实让我有了一些粗浅的发现。
总的来说这篇博客涵盖内容比较杂,包括dueling net简介,reward函数修改,wandb sweep超参搜索。
Dueling net 简介
dueling net 相比于 double net来说涉及到数学推理的部分更加的少了,核心思想就是一句话:
简化模型拟合分布的复杂度
它将DQN直接预测每个状态动作Q的范式改成了分别预测每个状态动作的V,A,再将V和A相加得出Q。
我们接下来会分两段讲:
1.How:如何得到最终的网络结构
2.Why:为什么要用这样的结构
1.How:如何得到最终的网络结构
我们先把它的数学表达式列出来:
$$
Q(s,a;\theta,\alpha,\beta)=V(s;\theta,\beta)+A(s,a;\theta,\alpha)
$$
这里的V代表的是状态价值函数,A则表示的是优势函数,也就是一个状态的每一个Q相对于状态函数V的差值。
对于表达式括号里的字母,我们先来看分号后面的$\theta,\alpha,\beta$。我们直接从神经网络的角度来理解。这三个字母表示的都是模型的参数,可以看到V、A两个函数公用了$\theta$这一部分参数但是同时这是因为网络的前几层可以理解为特征提取,是在对输入进行语义解析,是和输出弱相关的,可以公用。而$\alpha,\beta$则就是抽取完特征之后用于产生不同任务输出的任务头。
我们再来看分号前面的$s,a$,这就是模型的输入,状态函数的输入当然只有状态了,而优势函数当然既要有状态又要有动作。从神经网络的角度来理解的话其实无论是优势函数还是状态函数的输入其实都是只有状态的,至于说动作则是对神经网络的输出进行索引,倒也能算是概念上的输入。
这里要注意的是对于一个state的输入,会输出一个状态函数V以及n_action动作数量个A,当进行Q值的计算的时候,将V复制成n_action份进行加法。当然python会帮我们利用广播机制进行复制。
当然了,上面这个式子是不能直接用的,原文在这里提到了unidentifiable不定的,就是说我们最后是找不到一个唯一的解V、A满足等式。
或者说找到的V、A不是状态函数以及优势函数。
这并不是说求出来的Q不定,Q的更新是根据外部的框架来的。无论内部网络架构如何变都只会影响模型的复杂度(欠拟合、过拟合),影响Q的收敛速度(当然实质上来说收敛太慢=无法收敛)。
这里说的是对于一个固定的状态,对于它的所有状态、动作对,我们无论重复多少次实验,一定会收敛到相同的Q(就是动作价值函数)。
但是V、A每次却不一定相同。这是可以理解的,把V+x,把A-x就可以实现Q值不变的同时,V、A可以有无穷组取值。
有人可能会说,这重要吗?
只要最后的Q是对的不就行了?
其实不是这样的,Dueling net真正起作用的点就是要让V尽量拟合价值函数,这个我们接下来第二部分会说。
我们先接着讲怎么让V能够拟合到价值函数。
前面我们已经知道了,V之所以不能拟合到价值函数是因为A可以整体变化一个常数,从而让V整体变化一个常数。
但是相同状态,不同动作的A之间的差距是不会变化的,因为就是Q之间的差距。
也就是说,我们只要让相同状态下的一种动作的A值是真实的优势函数,那么所有A值就都是真实的优势函数,并且V值也是真实的状态价值函数了。
那么我们怎么让相同状态下的其中一种动作的A值是真实的优势函数呢?
或者说相同状态下的哪一个动作的A值我们可以将它固定为真实的优势函数,作为一个锚来固定其他优势函数呢?
有的,兄弟,有的,
那就是最大Q值对应动作的优势函数 恒为0
啥意思呢,就是说无论对于哪个状态,它的最大的优势函数都是0。
这是从价值函数的定义得到的,因为 价值函数 = = max(动作价值函数),那么很显然max(优势函数)= = max(动作价值函数)-价值函数 = = 0。
所以我们只需要让 $A^{*}(s)==0,s\in S$,那么A就是优势函数,从而V就是状态函数。
怎么做呢?
简单,用$A(s,a;\theta,\alpha)-\underset{a^{‘}\in \mathcal{A}(s)}{max}(A(s,a^{‘});\theta,\alpha)$ 代替$A(s,a;\theta,\alpha)$即可。
所以新的表达式就是:
$$
Q(s,a;\theta,\alpha,\beta)=V(s;\theta,\beta)+
(A(s,a;\theta,\alpha)-\underset{a^{‘}\in \mathcal{A}(s)}{max}(A(s,a^{‘});\theta,\alpha))
$$
根据这个表达式我们就可以让V拟合到状态函数,让$A(s,a;\theta,\alpha)-\underset{a^{‘}\in \mathcal{A}(s)}{max}(A(s,a^{‘});\theta,\alpha)$ 拟合到优势函数了。
到这里其实就已经将dueling net 表达式推导讲完了,但是论文作者又找到了一个改进版本的dueling net,就是将max改为mean,这一举动增加了稳定性,但是却是让数学上的解释部分失效了,表达式是:
$$
Q(s,a;\theta,\alpha,\beta)=V(s;\theta,\beta)+
(A(s,a;\theta,\alpha)-\frac{1}{N}\sum_{a^{‘}}{(A(s,a^{‘});\theta,\alpha)})
$$
2.Why:为什么要用这样的结构
为什么将动作价值函数分解为状态函数以及优势函数会使agent表现更好呢?
在我看来关键点就是简化模型拟合分布的复杂度。
对于agent的决策来说,只需要知道策略policy就足够了,并不需要知道更加复杂、信息量更多的动作价值函数Q。
但是对于强化学习来说(DQN系列),策略都是通过动作价值函数得来的,想要知道策略,我们必须先知道信息量更大的动作价值函数。
而dueling net则通过设计巧妙让模型拟合更加简单的分布:V、A。
这样A函数就可以当作策略了,因为它完全丧失了不同状态之间价值的信息。不同状态之间价值的信息则完全存储在V中。
而V相对于Q来说也是更加简单的,因为它完全丧失了不同动作之间价值的信息,不同动作之间价值的信息则完全存储在A中
那么前面为什么要让V拟合到价值函数就可以解释了,如果V不能看作价值函数,A不能看作优势函数,那么岂不是一部分的不同状态之间价值的信息要存储在A中,那么A不就又变成Q了,V啥作用都没起到。
那么为什么将取最大值变为取平均值网络仍然有效?
我不知道:)
这一部分的最后我把dueling net的网络结构展示出来,大家就知道这是多么简单的一个改动了。
1 |
|
将上面的dueling net的网络结构用于D2QN就变成了D3QN,可以说就是离散动作空间的毕业装了,下一步就应该学习连续动作空间的算法。
但是在这之前我用D3QN去解决mountain car的任务竟然失败了,相比是因为超参没设好,但是我又不是很喜欢手动调超参,于是打算去网上看看有没有答案可以抄,结果发现直接修改reward函数竟然就能有很好的效果,于是我就研究了一会reward函数,最后顺利解决mountain car任务。
reward函数修改
之前因为超参问题就在网上搜过很多相关资料,其中这一篇链接其实一开始就在讲环境设置问题,但是当时没有注意,现在回过头来看环境的设置确实是尤为重要的,特别是对于sparse reward的一类问题,如果能修改奖励函数那么将奖励函数修改为dense的肯定是一条捷径。(前提是你知道怎么改)
回到正题,我是在解决mountain car任务的时候修改的reward函数,事实上也确实有很好的效果,而我做的仅仅是对于加速度和速度方向一样的experience给予较大奖励,并且给terminated的reward设置较大。这是很符合直觉的,因为对于mountain car 这样的模型我有很清晰的expert knowledge,就是速度越快越好。
1 | import gymnasium as gym |
在这之外我对于acrobot的任务也尝试了修改reward,但是是很小的修改,一方面是因为acrobot本身就可以收敛,另一方面则是因为对于acrobot这个任务我其实是不知道要对哪些行为进行奖励,对哪些行为进行惩罚的。
这个任务虽然看起来不是很复杂,但是已经足够让我不知道如何设置奖励函数了。
难以想象一些真正现实场景的任务的奖励函数设置会是多么困难。
1 | class WrapperAcrobot(gym.Wrapper): |
对于这一次的reward function的修改我同时还利用了wandb 的sweep进行了超参搜索,这一部分就留到下一节来讲。
wandb sweep 超参搜索
在学习DRL的过程中,碰到的很多问题都是超参设置不合理引起的。但是手动调试超参是一件很耗费精力的事情,前几天了解到wandb的sweep功能是用来进行超参搜索的,于是就尝试了一下。
确实很好用,这里推荐读者自己动手去试一下。
关于如何利用wandb进行超参搜索,读者可以直接搜索 wandb sweep 关键词,查看wandb官方的docs以及tutorial。
我一共进行了两次超参搜索,第一次是针对lr、hiddensize、reward进行的,第二次是针对maxexperience、batchsize、gamma进行的。
接下来我会一一解释。
针对lr、hiddensize、reward 的超参搜索
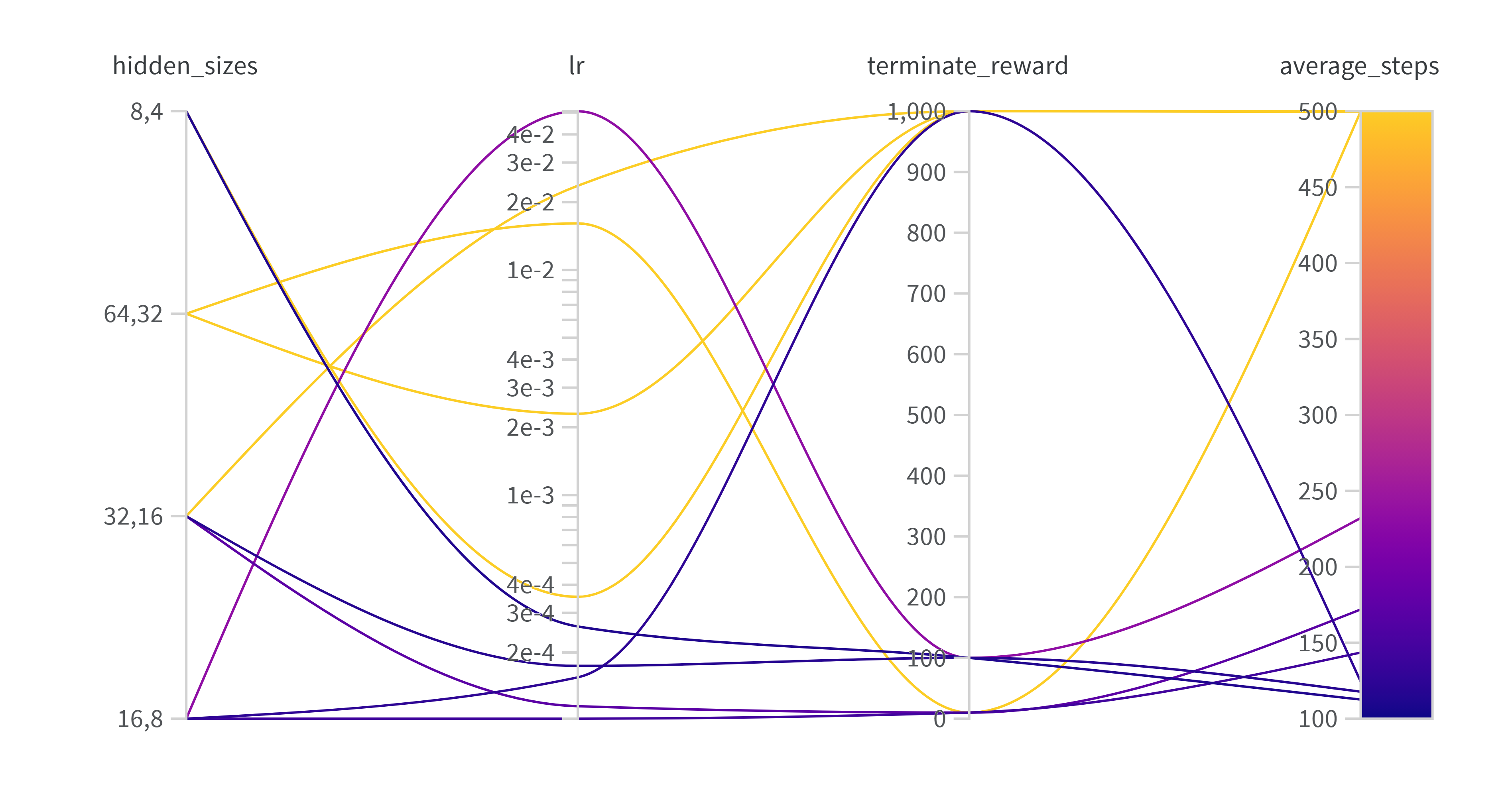
直接上图。图中任务为acrobot,总共进行了10次实验,相关设置代码如下: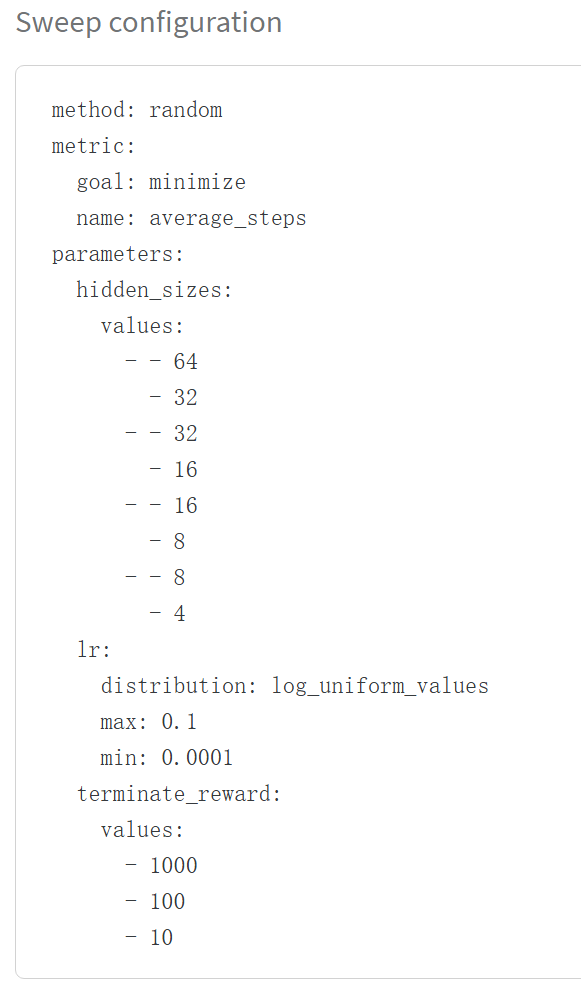
结果还是很直观的,对于这三个参数来说,真正于average step有关联的只有lr。
因为是acrobot任务,步数越少代表agent越早实现目标。
所以我们可以很清晰的得出结论:对于acrobot任务来说,较低的学习率是模型收敛的关键。
至于说模型本身的复杂度,恐怕关系没有那么大。当然了,我这里只跑了500个episode,所以较大的模型复杂度导致的过拟合现象可能会在之后才发生,而我这一次实验却观察不到。
至于说我之前特意调整的奖励函数,此时却是根本与结果无关。
针对maxexperience、batchsize、gamma的超参搜索
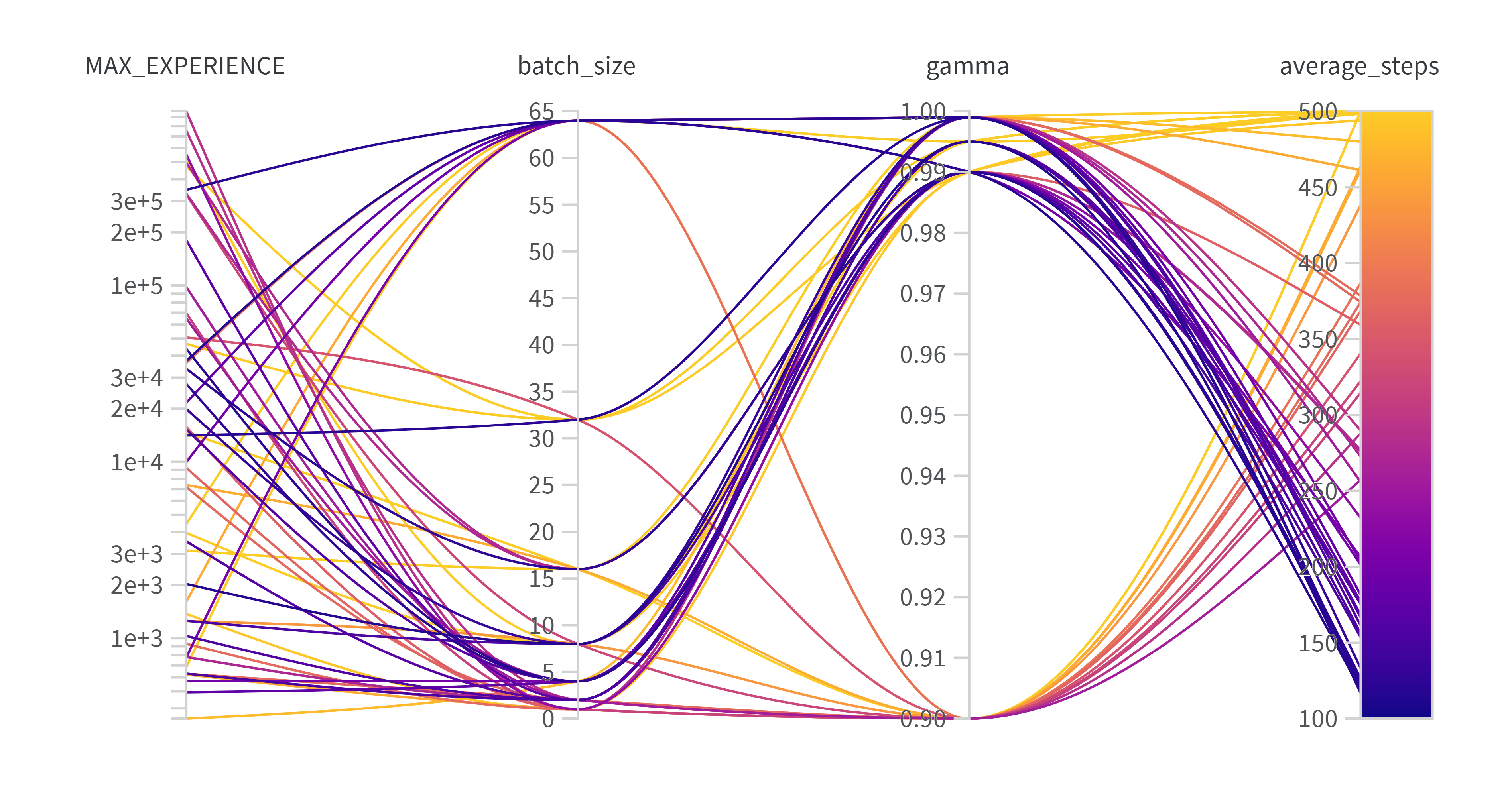
图中任务仍然为acrobot,相关设置如下:
从图中可以看到,过低的gamma明显导致了表现得下降,这与计算结果是吻合的,我们可以做出下面这样的分析:
对于gamma=0.9的agent来说,500步之后的reward还剩下多少呢?
${0.9}^{500}=1e-23$这已经和噪声没有差别了,就是说如果又500步才完成任务的trajectory,那么模型基本上很难从500步的reward学习到有用的东西。
当然了,这种一开始的成功的trajectory一般不会要完整的500步,扣除掉前期无意义的摇摆的话,我们就算它需要250步(已经是平均表现中较好的表现了),${0.9}^{250}=3e-12$,仍然和噪音没区别。
当然,你也可以说agent最快只需要100步就能完成任务,${0.9}^{100}=2e-5$,结果仍然太小。
而如果gamma=0.99的话,情况就好转很多了${0.99}^{250}=0.08$,这是一个很可观的数字,这代表着模型可以很轻易地从成功的trajectory中学习到成功的经验。
于是我们可以把gamma=0.9的实验去掉,于是得到了一副新的图: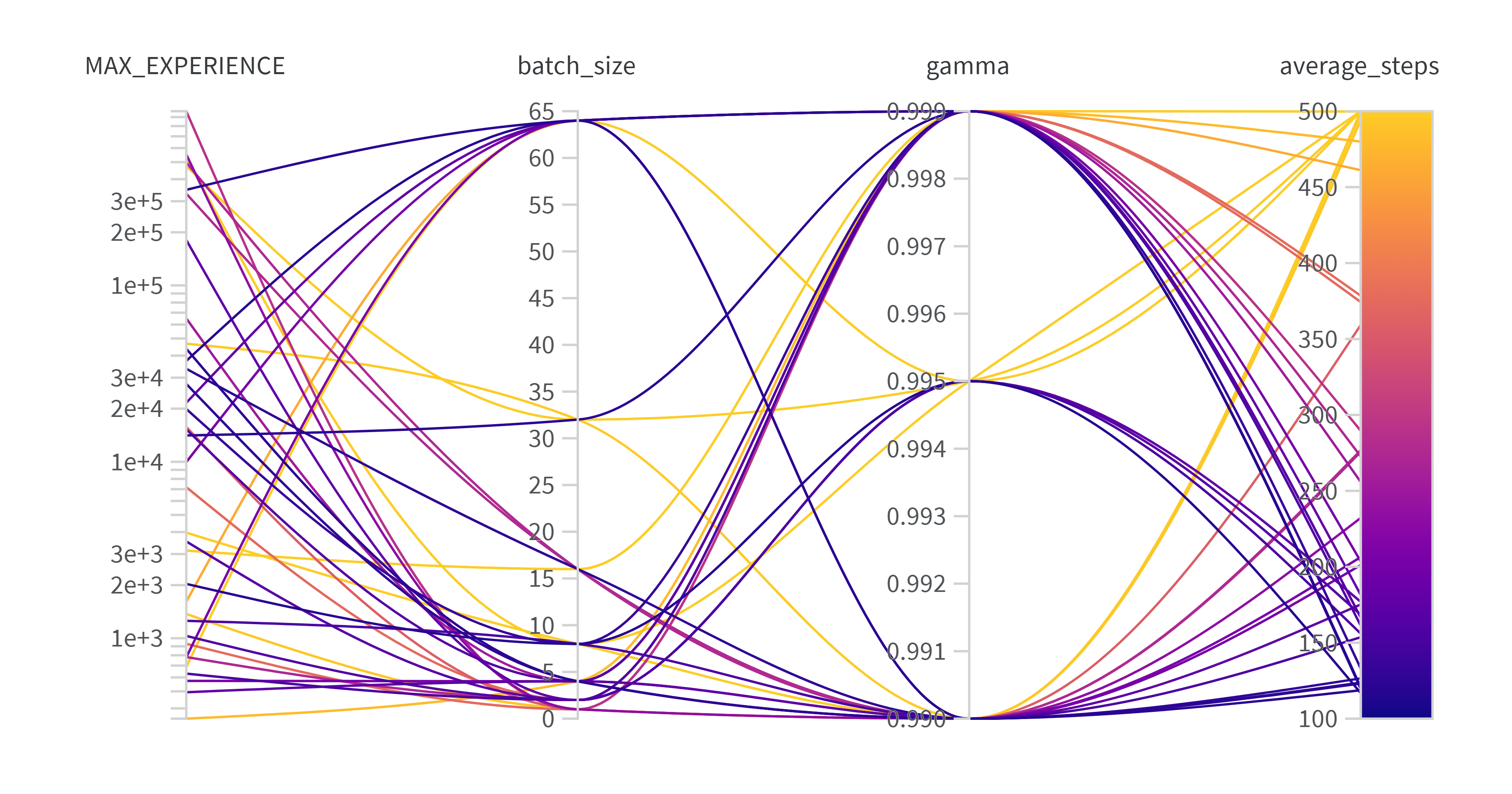
我从图中得到的结论就是replybuffer的大小以及batchsize的大小并不是一个敏感的参数。
所以我们可以得出结论了:drl模型训练中,lr应该尽可能地小,gamma则应该根据成功trajectory的可能长度而定。
说开来去
总的来说连续状态空间、离散动作空间的算法到这里就告一段落了,下一步就应该学习连续动作空间的算法了。
其实本来打算多在几个任务上试一试“毕业装”:D3QN的,但是gymnasium中大部分的任务都是连续动作空间的,只能作罢。
接下来的计划有两个,一个当然是连续动作空间算法学习,另一个则是尝试一下马里奥游戏的agent训练,毕竟让agent学会打游戏对我来说还是很有吸引力的。
reward 函数的修改以及超参搜索其实引发了我很多的思考。
对于sparse reward的任务直接修改env的reward function 是最容易有效果的(相比于超参搜索)。但是这样需要人类对任务有很好的理解,也就是expert knowledge。总不可能所有需要rl解决的问题都是人类研究透的吧,那要是没有expert knowledge 不就完蛋了。
但话又说回来了,如果不对每个任务重新设计超参,现有的rl算法有那种一个超参干掉所有任务的能力吗?