强化学习算法 Expert Iteration (EXIT) 论文解读
前言
最近在尝试看automatic Theorem proving 相关的论文,发现没见过的名词有点多啊。只能是把一些技术相关的原论文拿出来仔细研究一下。
其中Thinking Fast and Slow with Deep Learning and Tree Search(论文)就是强化学习相关的,看它与我有缘,那就从它开始吧。
核心方法
这篇论文洋洋洒洒讲了好几页,其实核心方法是很简单的,主要是它在核心方法之外加了一个又一个的trick,使得我们的注意力容易被误导。
对于EXIT方法来说,核心是要维护两个决策模型。
一个是推理速度快,但是正确率较低的(指的是一开始正确率低,经过整个算法迭代后正确率会提升到与另一个模型相当的水平),被称作apprentice(学徒),表示为$\hat{\pi}$。
另一个则是推理速度慢,但是正确率较高的,被称作expert(专家),表示为的$\pi^*$。
EXIT方法的主要过程就是以expert模型作为监督信号更新apprentice模型。
但是论文中还着重强调了利用变得越来越强的apprentice模型提高expert的探索效率与正确率,这个我们后面再讲,先还是讨论最核心的方法。
上面是算法的伪代码,但是里面包含了很多的trick,所以我们先根据EXIT的核心方法,给出一个最naive的伪代码。
下面是最最最核心的算法伪代码.。
这是很容易理解的,初始化apprentice这个模型(这里我们用神经网络)
,然后用expert产生的的数据集(注意!这里并没有一个expert模型,只是有一个由expert产生的数据集,数据集中的样本的形式是状态动作对)不断训练apprentice模型。
这就是最简单的模仿学习imitation Learning范式了。
接下来我们不断添加trick,尤其是引入interactive交互的expert模型,并且让expert模型根据apprentice模型提升,让算法变为最终版本。
DAGGER algorithm
我们先来改变$\hat\pi_i=train_policy(D)$,也就是apprentice模型只能够根据一个expert产生的固定的数据集进行训练。
有人会问,这有什么不好的吗?
这当然不好了,因为expert产生的数据集难道能包含所有的状态动作对吗?如果能够包含所有的状态动作对,那自然没啥问题了,直接让apprentice根据状态查表就行了。
但是事实上expert产生的数据集是很局限的,只能覆盖一小部分状态动作对。
那么只要我们的agent遇到了expert数据集中没有的情况,就会有很大概率出错了(相当于老师没有教你的题型你就不会做了)。
这个问题如果用机器学习的话解释就是训练数据集的分布和测试数据集的分布相差较大,并且模型泛化性不足以弥补这个差距。
针对这个问题,有一个很自然的解决方法,就是让专家一直在线,agent不断与环境进行交互,专家则对每一次的交互都进行修正。(相当于老师跟在你身边,你做一道题就给你打分,并且把正确答案告诉你让你现场学)
这样就相当于是让训练数据集和测试数据集(也就是agent可能遇到的状态)尽可能的靠近了,减少了分布之间的差距。
当然了,为了模型更新的效率,我们实际上是先进行一定数量的交互,然后让expert一次性根据一个batch的状态给出正确动作,产生一批新的数据集,然后让apprentice学习这批数据集,然后重复。
我们的伪代码就可以升级成下面的形式。

如果读者注意看的话会注意到,这里的apprentice模型的更新是只根据每一次的数据集$D_i$训练而来,并且完全和上一次的apprentice无关。
那么这就要求每一次的数据集大小足够的大才行。
但是实际上让专家对状态给出正确动作的代价是很大的,需要消耗很多的时间。
有没有一种方法可以减少每一次的数据集的大小,但是还是能保证每一次训练的数据不下降呢?
这就是这一章的标题DAGGER了。
DAGGER具体来说就是维护一个从开始以来产生的所有数据集的集合,也就是说每一次生产的新的数据集只是作为训练数据集的补充,前几次迭代的数据集仍然参与之后的apprentice训练。
我们的伪代码可以进一步的修改。
(注意此处的伪代码已经和原论文中不以言了,笔者认为只是因为原论文作者加的trick太多了,原论文作者也难免有所遗漏)
imitation_learning_target
读者可能会有疑惑,这个imitation_learning_target() 是什么函数呢?
其实这就是一个关于损失函数Loss的选择。
当我们选择不同的 imitation_learning_target ,相当于我们选择了不同的用于imitation_learning的损失函数。
论文一共提供了两种损失函数,我们分别来讲。
chosen-action targets(CAT)
直接上公式
$$
\mathcal L_{CAT}=-log[\pi(a^|s)]
$$
这里的$a^$就是expert所选择的动作。
这个损失函数的本质就是交叉熵函数,我们的expert被认为是一个“自大狂”,它对自己采取的行动有着百分百的置信度。
这显然不是一个很好的损失函数,或者说这不是一个很好的expert。
expert给与学徒模型的知识太少了,expert只告诉学徒说,你要这样做,却没有说这样做的可信度是多少,以及其他做法之间的优劣关系。
而这些信息对于模型对整个任务的理解是至关重要的。
tree-policy targets (TPT)
TPT 是论文最后选用的损失函数,我们直接看公式
$$
\mathcal L_{TPT}=-\sum_a\pi^(a|s)log[\pi(a|s)]
$$
这里的$\pi^(a|s)$就是expert给出在给定状态下各个动作的概率。
显而易见的是这个损失函数是更合理的,学徒模型可以学习到更多的expert的知识。
有些人可能会疑惑,为什么这个损失叫tree-policy targets?
(实际上并不是损失是tree-policy targets,而是标签是tree-policy targets,而这个标签导致了这个损失,但是为了简便这里就不加区分了)
实际上这是因为我们的expert是一个tree search模型,也就是树搜索策略,我们下一节就会讲到。
Monte Carlo Tree Search

我们看回到这个伪代码,$\pi^$到底是什么呢?
在论文中$\pi^$是一个 Monte Carlo Tree Search 模型,而这个模型是不需要任何先验的,所以实质上来说,这根本就不是一个imitation learning 的范式,因为根本就没有一个所谓人类的知识让模型学习。
回到正题,我们来解释一下什么是 蒙特卡洛树搜索。
蒙特卡洛方法大家肯定都已经十分熟悉了,这可以说是理解强化学习的基础概念。
蒙特卡洛的核心思想就是用随机采样而来的统计数据来近似事物的真实分布
想要深入理解蒙特卡洛树搜索也要抓住这一思想。
我们先展示一下蒙特卡洛树搜索的算法结构图。
(图片来自【最佳实战】蒙特卡洛树搜索算法)
蒙特卡洛树的每一个结点都是一个状态,每一个边都是一个动作。
树的根节点是我们感兴趣的状态,最终我们得到的就是一个树的根节点对应状态的各个动作的概率分布
(注意这里的状态空间是离散的,动作空间也是离散的。
世界模型的转移分布是确定的,也就是每一个状态动作对所对应的下一个状态是固定的,所以才能这么表示。)
对于每一个结点,我们要维护的信息除了 状态信息 就是 结点在[选择+拓展]阶段被访问的次数 以及 孩子节点是否完全被访问 。
对于每一个边,我们要维护的信息除了 动作信息 就是 边在[选择+拓展]阶段被访问的次数 以及 反向传播阶段的奖励 。
这里要注意的是我们不会将奖励记录在状态中,而是动作中,毕竟我们需要的是一个决策模型。
下面我们来仔细地说一说这四个阶段。
(注意,本算法博主并未实践、具体实现可能有差异)
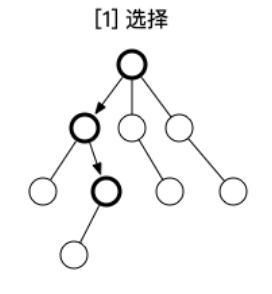
选择阶段我们需要做的就是从树的根节点开始,按照一定的规则选择一定的动作序列,直到遇到孩子结点未被完全访问的结点。
这里的一定的规则就是根据动作的分数进行选择。分数的计算则需要利用到我们之前所存储的信息。
具体公式如下:
$$
UST(s,a)=\frac{r(s,a)}{n(s,a)}+c_b\sqrt{\frac{log n(s)}{n(s,a)}}
$$
其中$r(s,a)$即边所存储的反向传播阶段的奖励,在第四阶段进行更新。
$n(s,a)$即边在[选择+拓展]阶段被访问的次数,在第一第二阶段进行更新。
$n(s)$结点在[选择+拓展]阶段被访问的次数,在第一第二阶段进行更新。
这个分数公式的选择是很合理的,对于公式的左边部分,也就是$\frac{r(s,a)}{n(s,a)}$,代表的exploit(利用)的部分,也就是说这个动作的价值(赢的概率)越高,那么分数更高。
对于公式的右边部分,也就是$c_b\sqrt{\frac{log n(s)}{n(s,a)}}$,代表的是explore(探索)的部分,也就是说动作被访问次数在当前状态所有可以选择的动作的访问次数中所占的比例越少,分数更高。
最终返回的监督信号也是根据分数而来的。
值得注意的是,这里的分数因为第二项$c_b\sqrt{\frac{log n(s)}{n(s,a)}}$的引入已经不能直接理解成概率了(因为加和已经不为一了),所以作者在将根节点的各个动作的分数转化为概率这个监督信号的时候用了softmax。
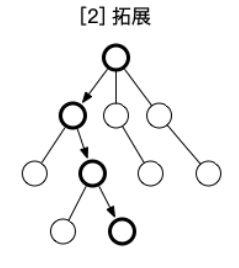
拓展阶段就是在选择阶段遇到孩子节点未被完全访问的情况是,随机选择一个未被访问的孩子节点所对应的边和结点,他们访问次数加一。(注意此处环境模型是deterministic的,所以一个状态动作对所对应的下一状态是固定的)
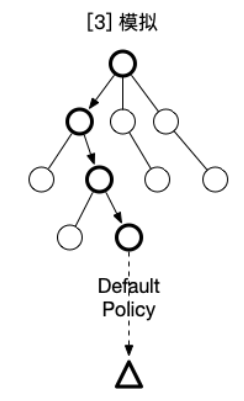
模拟阶段就是以拓展的的状态结点为起始,根据随机策略执行动作,直到环境给出terminated信号。
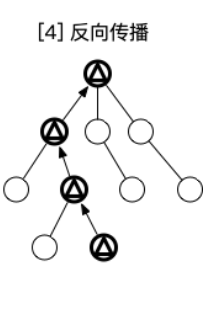
反向传播就是根据环境在结束时所给出的奖励信号,向上追溯复制给每一个结点和边(注意这里的discounted rate=0,并且在原论文的HEX任务中所给的奖励也并不是常规意义上的reward信号,而是胜利为一,失败为零的标记信号)
了解了蒙特卡洛树搜索的四个阶段我们就是到了它为什么叫蒙特卡洛了,因为第三阶段就是在随机采样,
第四阶段就是在通过速记采样的结果估计真实分布
Using the Policy Network
上面描述的是一个标准的蒙特卡洛树搜索的框架,这已经是一个很标准的expert模型,缓慢但是正确率较高。
但是如果大家回顾原论文给出的伪代码的话,会发现expert模型(也就是蒙特卡洛树搜索)的建立是将学徒模型作为参数的,也就是利用了学徒模型的信息,并且在每一次学徒模型更新后expert模型也会更新。
这也是这篇论文的核心观点:
利用变得越来越强的apprentice模型提高expert的探索效率与正确率
我们是如何在expert模型中引入apprentice模型的信息的?
直接上公式:
$$
UST_{P-NN}(s,a)=UCT(s,a)+w_a\frac{\hat\pi(a|s)}{n(s,a)+1}
$$
可以看到直接引入了一个额外的分数计算项,这个项直接与原有的apprentice模型的概率预测呈正相关,也就是说expert模型会把学徒模型的看法当作先验。
而随着expert模型内部迭代次数增多,动作被访问次数增多,学徒模型所带来的先验也被稀释了。
这是有效果的,特别是当树搜索的搜索空间很大的时候,apprentice先验的引入可以让expert模型的搜索更有效率,对于概率较高的动作给予更多的关注(也就是更多的迭代次数),使得其分数更为精确。
同时apprentice先验随着迭代次数的增加影响逐渐变小,也让expert模型有更好的探索能力。
其实我们可以换一个角度理解第二项。
从本质来说他就是一个optimizer中的动量,或者说是soft target update(软更新),减少每一次监督信号和模型的差距,是模型的更新更加稳定。
Using a Value Network
除了将原有的apprentice模型引入expert模型之外,论文还将 value network 引入expert模型。具体的做法就是在每一次拓展新节点的时候,都用一个value function计算新节点的value,并像第四阶段一样回传到父节点、边,在计算分数的时候也要加权上这个值。
要注意的是,这个value并不是我们通常强化学习理解的value function,它仅仅只是对于当前状态对应的terminated状态的reward是1(也就是胜利)的置信度(最大为一,最小为零)。
具体实现我就不细说了,有兴趣可以看原论文
引入了学徒网络的模型后,我们的伪代码又可以更新了,现在是:
这就已经和论文中的伪代码很相似了,甚至比原论文还要详细。
原论文还有很多的细节,我就不一一讲述了,有兴趣可以直接阅读原论文。
说开来去
这篇论文没有什么难以理解的想法,更多的是将很多细小的trick组装了起来,但是这种论文组织形式对于入门者来说是很不友好的。
论文中其实也有一些消融实验,但是更多的消融实验其实都要在论文的引文查看(毕竟不是新提出技术)。
对于新手最重要的还是动手自己设计几个消融实验跑一下,这个我有时间肯定会做的。