计算机视觉算法 DINO 论文解读
前言
之前了解过很多的cv模型,但大多都是知道个大概。
考虑到如果以后想研究具身的话,cv的前置知识是不可或缺的,于是打算把cv的里程碑式工作过一下。
今天看到Emerging Properties in Self-Supervised Vision Transformers(DINO)这篇论文,觉得很有意思,写篇博客总结一下自己的看法。
要注意的是,我并没有很多的cv前置知识,所以对于文中的很多技术的理解肯定是有偏差甚至错误的,希望大家宽容看待。
核心观点
具体的来说,DINO是一种训练模型的宏观的方法论,对于具体应用的模型框架是没有太多的要求的。
DINO的训练目标可以理解为让相似(指语义信息)的图片拥有相似的特征表示,不相似的图片拥有不相似的特征表示。
DINO是 *self-distillation with no labels* 的简称,抓住重点的话就是 self-supervised Learning(自监督)方法 和 distillation(蒸馏) 方法的总结。
下面我们从这两种方法看看DINO这个方法是如何达到我们上面所说的训练目标的。
自监督
自监督就是不依赖于额外的标注,利用原始的数据进行训练。
作者的方法中自监督的部分就是对同一张图片进行数据增强,产生n张数据增强后的图片,然后将这n张图片输入模型,要求模型的输出尽可能的相似。
但是直觉上也会发现不太行得通,因为损失函数只和前半句目标相关,因此我们就只能让相似图片有相似特征表示,却无法阻止不相似的图片拥有相似的特征表示。
这样的模型是没有意义的。
(模型很容易就会找到一条捷径,那就是让所有的输入映射到相同的输出。也就是模式坍塌)
一般的自监督方法是通过构建正负样本对来解决这个问题的,而DINO则是通过一系列的特殊处理使得模型不找这样的捷径,这个我们后面再细讲。
蒸馏
蒸馏就是将一个强大、笨重(表现好、参数大)的模型当作教师(也就是标注的生产者),监督一个更加轻量化的模型达到相似的强大效果。
作者的方法被称为“自蒸馏”,也就是教师的权重来自学生。
具体地说就是教师的权重是不会根据梯度更新的,而是来自学生的复制。
但是这个复制是被延后的,是在一个epoch之后将教师的权重替换为学生的权重。并且也不是完全的替换,而是利用了EMA指数移动平均的技术。
(关于EMA其实用的挺多了,之前学习DQN的时候就会发现很多的算法实现仓库都会利用EMA来延缓目标网络更新的速度。)
因此我们可以对自监督中说的方法进行更新,被数据增强过后的n张图片并不是放到一个模型中进行处理,而是复制两份分别放入教师、学生网络进行处理,要求两个网络的输出尽可能相同。
(值得注意的是对于相同的数据增强的图片,并不会计算它们的输出相似度作为监督信号)
具体的示意图如下图所示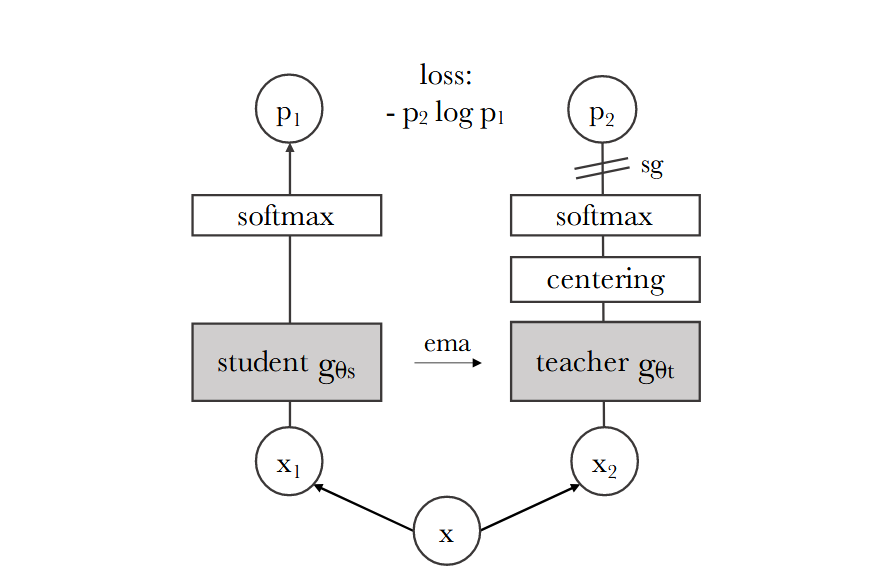
蒸馏的核心观点:从一个更强的expert中学习知识。
而这个更强的expert有着各种各样的缺点,比如:参数量大(传统蒸馏)、计算耗时(mcts)…
但是我个人觉得作者这里提出的自蒸馏反而不能严格称之为蒸馏了,因为教师网络并没有比学生网络更加强大。
(在动量更新的技巧下,教师网络确实是比学生网络要强,但是我觉得这并不是这篇文章的核心卖点,因为哪怕是不进行动量更新,教师网络不强于学生网络的前提下,整个DINO框架还是可以很好的收敛的。)
核心观点总结
那么我们现在就有了一个只包含核心观点的DINO算法,它当然是不完善的,因为他缺少了两个核心组件,也就是解决自监督中我们提到的模式坍塌问题的关键。
但是我们还是先将核心算法用伪代码表示出来,便于一步一步的理解
黑线部分是我们接下来需要补足的。
(不想写伪代码了,凑合一下)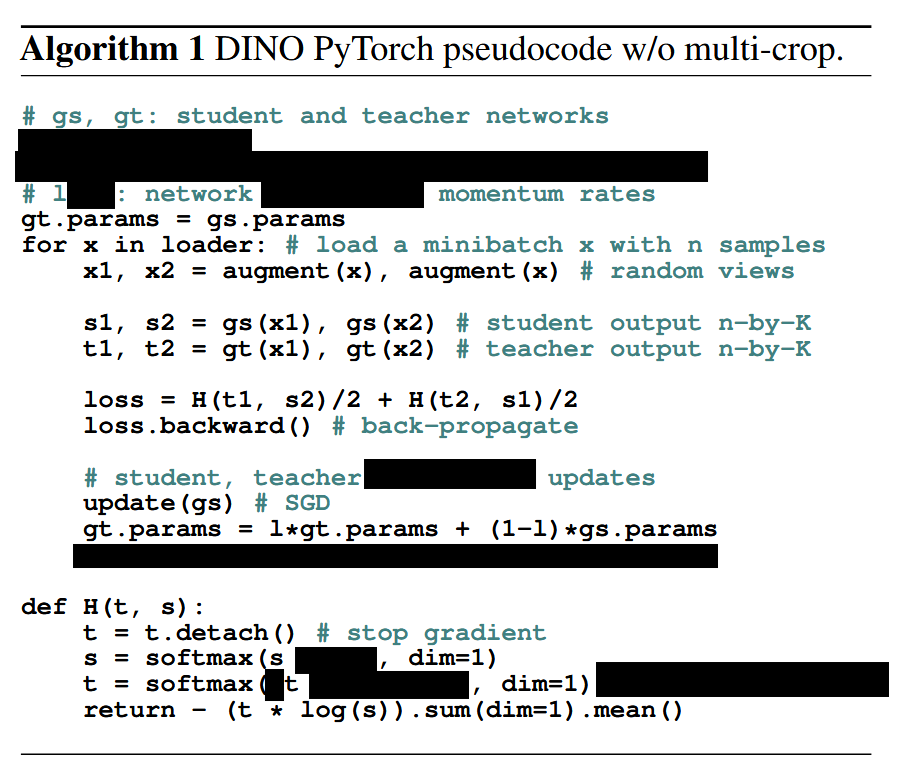
中心化以及锐化
中心化、锐化就是作者用来防止模式坍塌的两个利器,按照作者的实验结果,这两个工具已经不是提多少点的程度了,是没有的话根本就训练不出来,会模式坍塌。
下面这张图就很好的说明了两个工具的重要性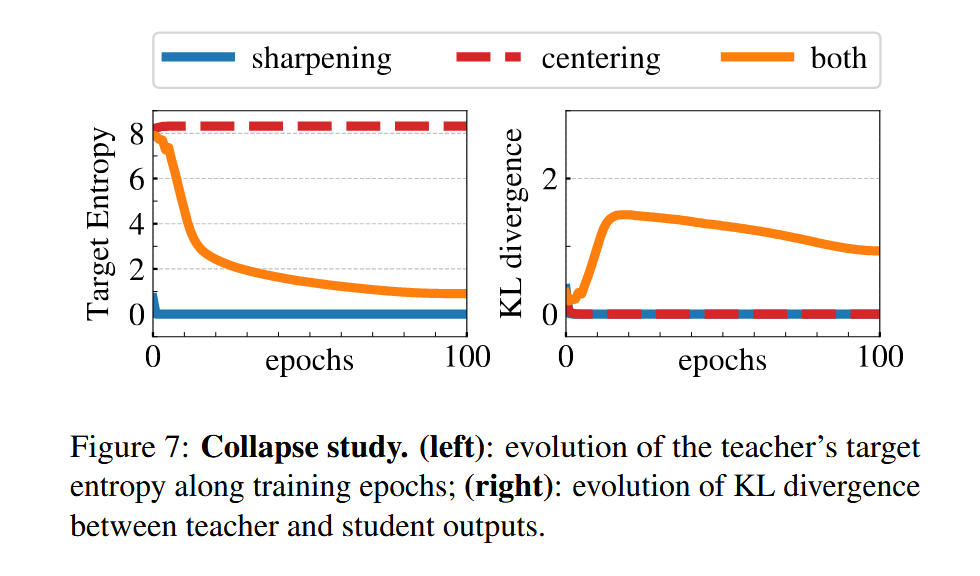
这张图是对于这两个工具的消融实验。
先看右边的图。
学生网络和教师网络的kl散度为0代表两个网络的输出一样,代表“收敛”?
这里的收敛是打引号的,对于橙色来说确实是正常收敛了(kl散度逐渐趋向于0),但是对于红蓝色来说,则是模式坍塌了。(直觉上来说,模型不可能在那么短的时间内就收敛,只有可能是模式坍塌了)
所以只有同时使用这两个工具才能防止模式坍塌。
接下来我们分别讨论中心化和锐化以进行更细致的分析。
中心化
中心化就是记录下教师网络的之前的所有特征输出的加权和,并在计算当前教师网络输出的时候减去这个记录特征。
离当前越近的特征的权重越大,在具体的实现时作者在每一个epoch结束时对记录特征进行指数移动平均更新。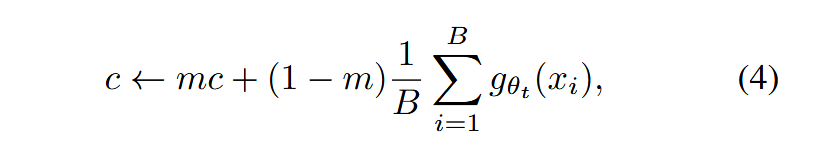
这样做有什么样的好处呢?
最直观的就是起到了归一化的作用,如果某一维特征特别的大的话,那么记录特征的这一维也会特别大,那么教师网络的输出的这一维就会变小,作为监督信号强迫学生网络降低这一维的特征。
但是这也有坏处,这回减少特征不同维度之间的差异,导致最后的结果变成了均匀分布,我们从左边的熵函数可以看出,单独使用中心化会导致特征的熵特别大。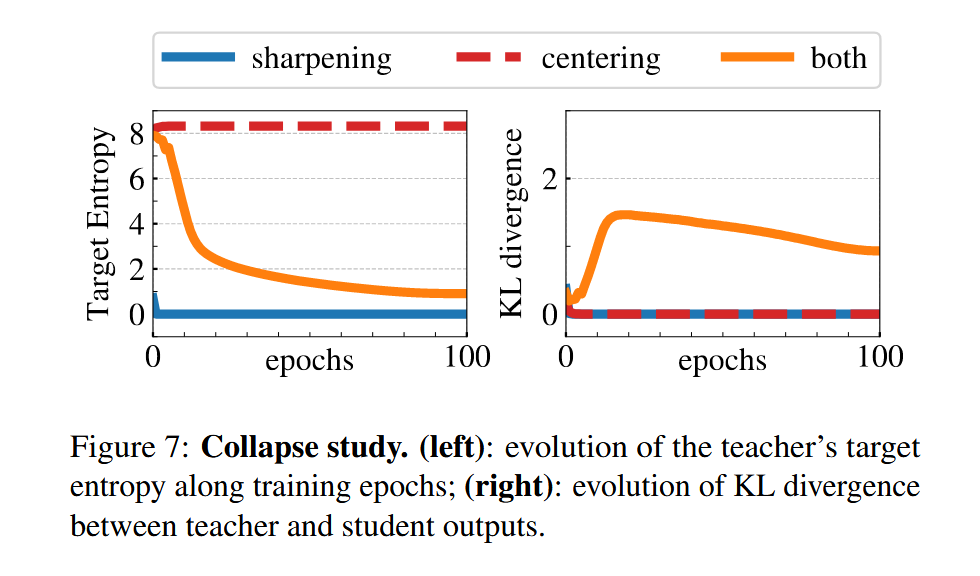
锐化
锐化又是在干嘛呢?
顾名思义,其实就是将softmax的温度系数调低一点,这样就可以让特征更加的“贪婪”(也就是让特征不同维度的之间的差距拉大),从而起到避免特征各维度变成均匀分布的作用。
但是他也有副作用,就是他会让特征的优势维度具有“统治性”,也就是特征图只有优势维度有值,其他维度都是0。(其实很容易理解,本身输出的是logist,经过softmax就是一个指数级的缩放,缩放前还通过低温加大缩放比例)
中心化和锐化总结
作者通过两个关键工具通过互相拉扯成功避免了模式坍塌,这还是很有技巧性的。
那么现在的伪代码就是这样的。
其他关键技术
作者还用了很多的小技巧来提升模型的学习效果,论文中也做了很多消融实验。我们就挑一些讲一讲,感觉如果有时间的话仔细琢磨琢磨作者的一系列消融实验应该还是能得到很多信息增益的。
例如下面这张表。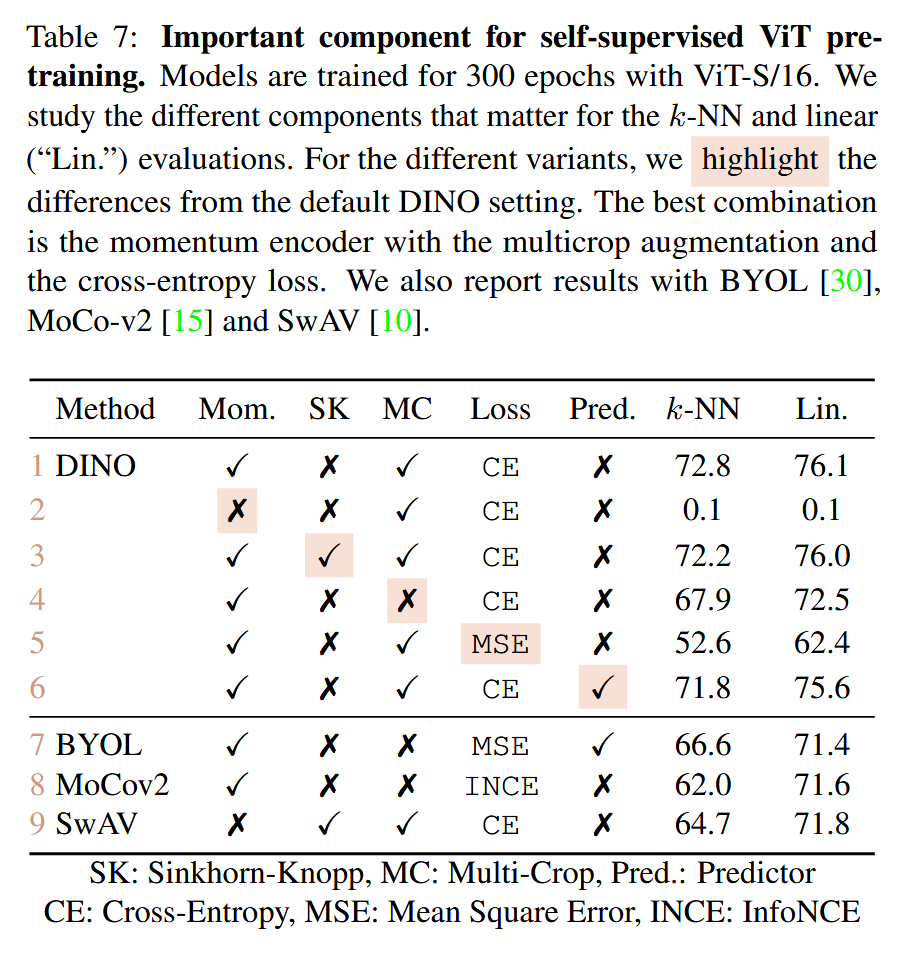
其中的mc也就是将多个经过数据增强的裁剪过的小patch输入学生网络,然后在教师网络的监督下学习。
这其实是很符合直觉的,要求模型通过局部信息推出全局信息,如果模型的复杂度达到某个界限,使其可以完成这样的任务的话,那么更加困难的任务显然可以增强最终的模型能力。
其中的loss函数的对比试验也很有意思,我不知道这里的mse在使用中有没有取消输出层的softmax,因为一个很显然的结论就是ce更加适应分布之间的对比,softmax之后的输出不就是分布吗,适合ce是理所应当的。
总结
DINO是一个自蒸馏的训练方法,通过让模型学习相似的输入应该有相似的特征,并加上一定的约束,成功的让模型能够建模输入之间的关系,并将这种关系映射到一种特征空间。通过DINO方法训练出来的模型拥有着强大的特征抽取的能力,可以很方便的通过一些小改动应用到下游任务中,后续也出现了一系列影响力巨大的模型,例如 depth anything,利用DINO训练的模型作为backbone,在fine tune 之后很好的完成了深度估计的任务。
说开来去
DINO最让我觉得有意义的是它的自监督范式,这种不需要人工标注的训练方式很明显有着巨大的潜力,这在nlp中早已得到证实。
但是在实现中DINO却需要两个关键组件来防止模式坍塌,确实有点不优雅。
文本信息是天然有序的,由此人们利用这种有序性实现了大规模的自回归的自监督训练。
但是图像信息应该如何实现大规模的自监督训练呢?
后补:
对于原文中的这张图
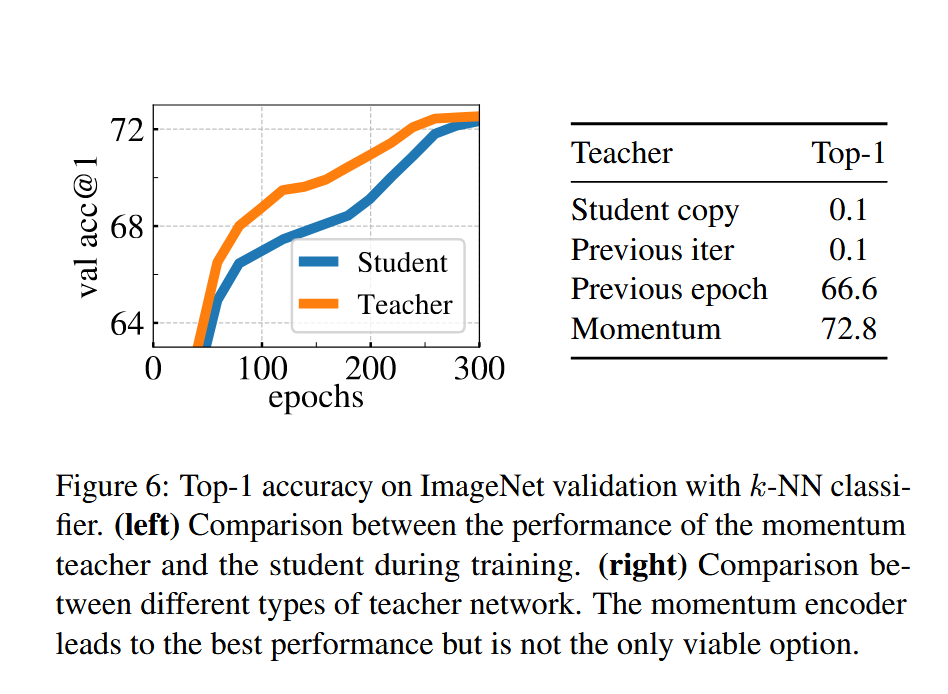
我一直都有疑惑,为什么教师网络会优于学生网络呢?原文给出了一些相关文献,我暂时还没看,但是在dqn的target net的更新中也用到了ema的更新方式,我觉得target net也可以看作是一种教师网络。
于是我就将dqn训练过程中的target net 和main net 的评估表现进行了对比,结果发现确实是target net 会优于 main net。
(橙色为target net,蓝色为main net,实线为高斯光滑后结果)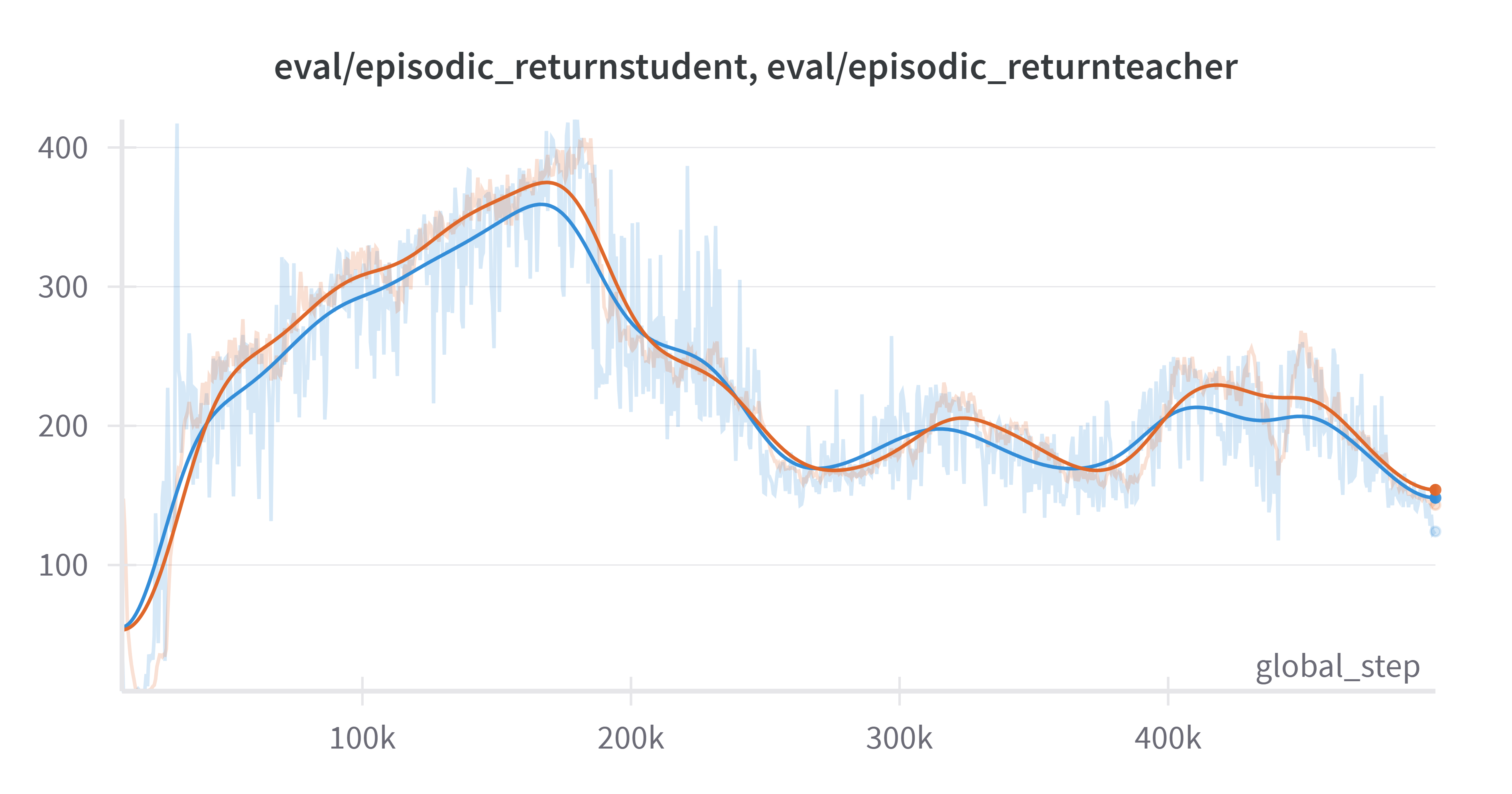
此处我的tao(也就是每次更新新的权重的大小)设置的太小了,是0.1,所以影响网络收敛了,但是大体趋势还是可以看出target net 确实效果较好。
回过头来看自己的dqn实现,应该是保存target net更好,自己却是忽视了这一点。
只能说学无止境啊。