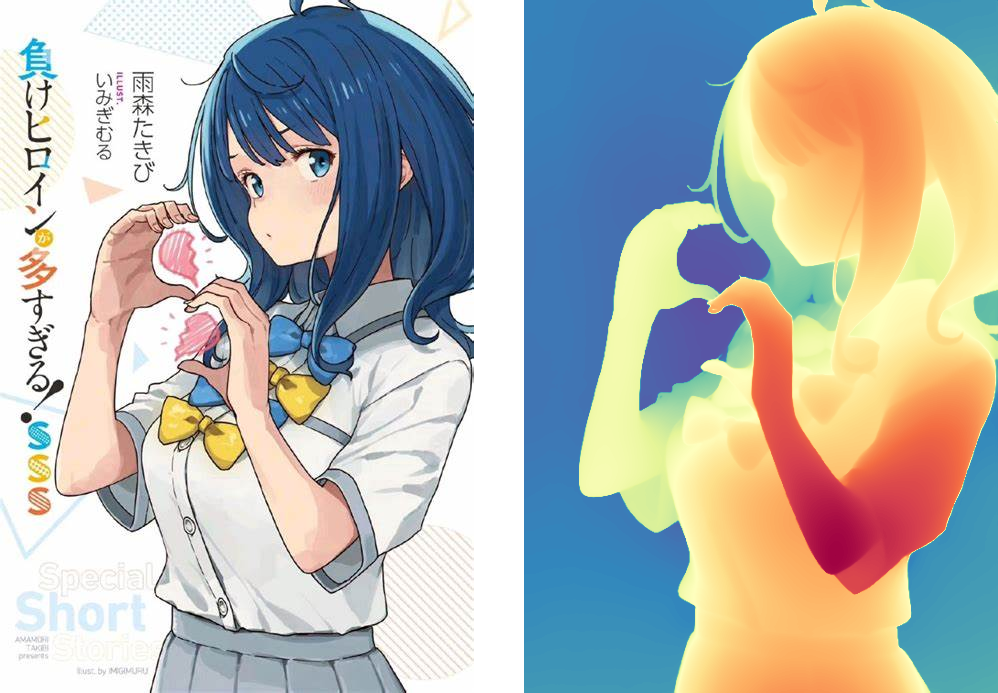
计算机视觉算法 DINOV2 论文解读
前言
看完了DINO这篇工作,整体还是很有收获的,也是很期待DINOV2会给我带来什么惊喜。
但是真的看完整篇论文才会发现其实给我带来的信息增益不是特别的多。
跟我学llm时候的情况很像,想要以llama系列的技术报告为支点熟悉llm的体系框架,但是后面几个版本的技术报告内容中的部署细节很多,很难学到目前用的上的只是。
DINOV2也花了一些的篇幅在部署细节上,对于这一部分我仍是味同嚼蜡。因为这一部分内容很难通过 理论学习+跟着代码执行过一遍流程 学习方法吸收。
但是DINOV2和一代一样做了很多下游任务实验证明方法训练模型所抽取的特征是很好的特征,这一部分我很感兴趣,填补了我对这些下游任务实现的空白(是我见识少的缘故)。
(同样,我对作者提及的其他对比算法了解十分有限,所以表述难免错漏。如有发现,欢迎在评论区指出)
DINOV2
训练数据
论文在数据处理上花了挺多篇幅,但是我觉得结论不太能说服我。
DINOV2的数据处理分为三部分:数据获取、数据去重、数据检索。
数据获取
图像数据源于网络爬取,将爬取内容中的img tag对应的url内容下载下来。(去除不安全或域名限制访问的url)
然后进行了简单的主成分哈希去重、nsfw过滤、面部模糊。
数据去重
数据去重分为两部分。
首先对于爬取的图片进行压缩(这里利用已有的embedding层),然后根据图像embedding之间的余弦相似度进行knn,将每个图像embedding的 64个以内&&余弦相似度>0.6 的最近邻保留,据此构造并查集,每个集合保留一个图像。
然后将与 之后要用到的benchmark 的测试集评估集中的图像嵌入 余弦相似度大于0.45的图像去除。
数据检索
根据已有的benchmark 训练集的图像 对经过以上两步处理过的爬取图像进行检索。
对于大小不一的训练集操作不一样,但总之就是尽量检索相似的图像。
经过三个步骤后的图像,还要再加上一些benchmark原有的训练集,就是最终的训练数据了。
我给大家看一下作者给出的最终训练数据表。
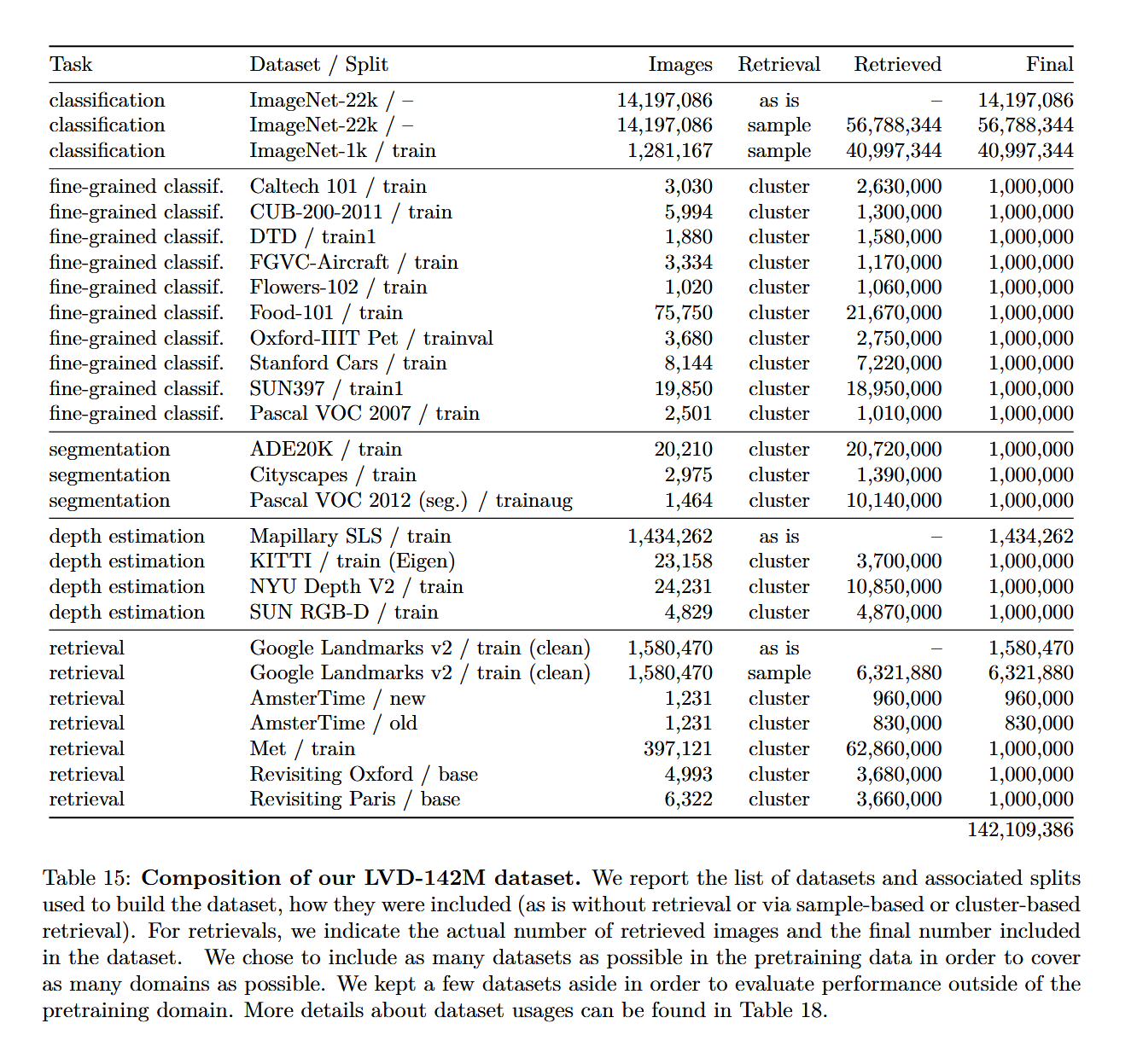
这个训练数据在消融实验部分根据作者的对比表现不错。
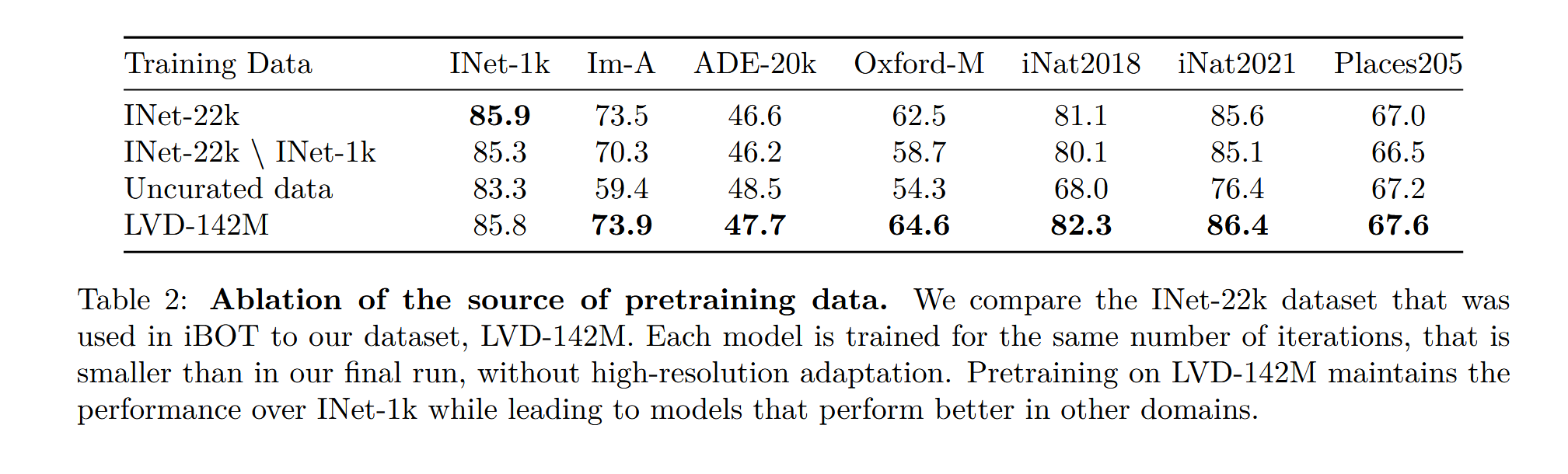
但是这里我觉得是有问题的。就拿第一行举例,inet-22k训练出来的模型在inet-1k中表现更好,你说是因为它包括了inet-1k的训练集,所以把inet-1k的训练集去掉后,lvd-142(作者提出训练集)的表现就更好了。
但是,你lvd-142中包含有根据inet-1k采样过的数据,数据分布可以说有一部分和inet-1k很像了,这种对比不公平。
再说和uncurated data的对比,也是有点小问题的。作者这里想要证明的是精炼的数据对于模型的表现有提升,但是ade-20k、oxford-m都是数据检索过程中用的数据集,你根据它们的训练集进行精炼,在他们测试集的表现比精炼前好,这不是理所当然吗?至于uncurated data最后三个测试集的结果对比,确实可以看出lvd-142m比精炼前的训练效果更好了。
但是,我认为最好的对比应该是lvd-142m与测试集对应的训练集进行对比,并且胜出。
(后补:ade-20k的黑体标错了,难绷)
提升性能的训练组件
作者对于对ibot的改动之处做了消融实验,如下图: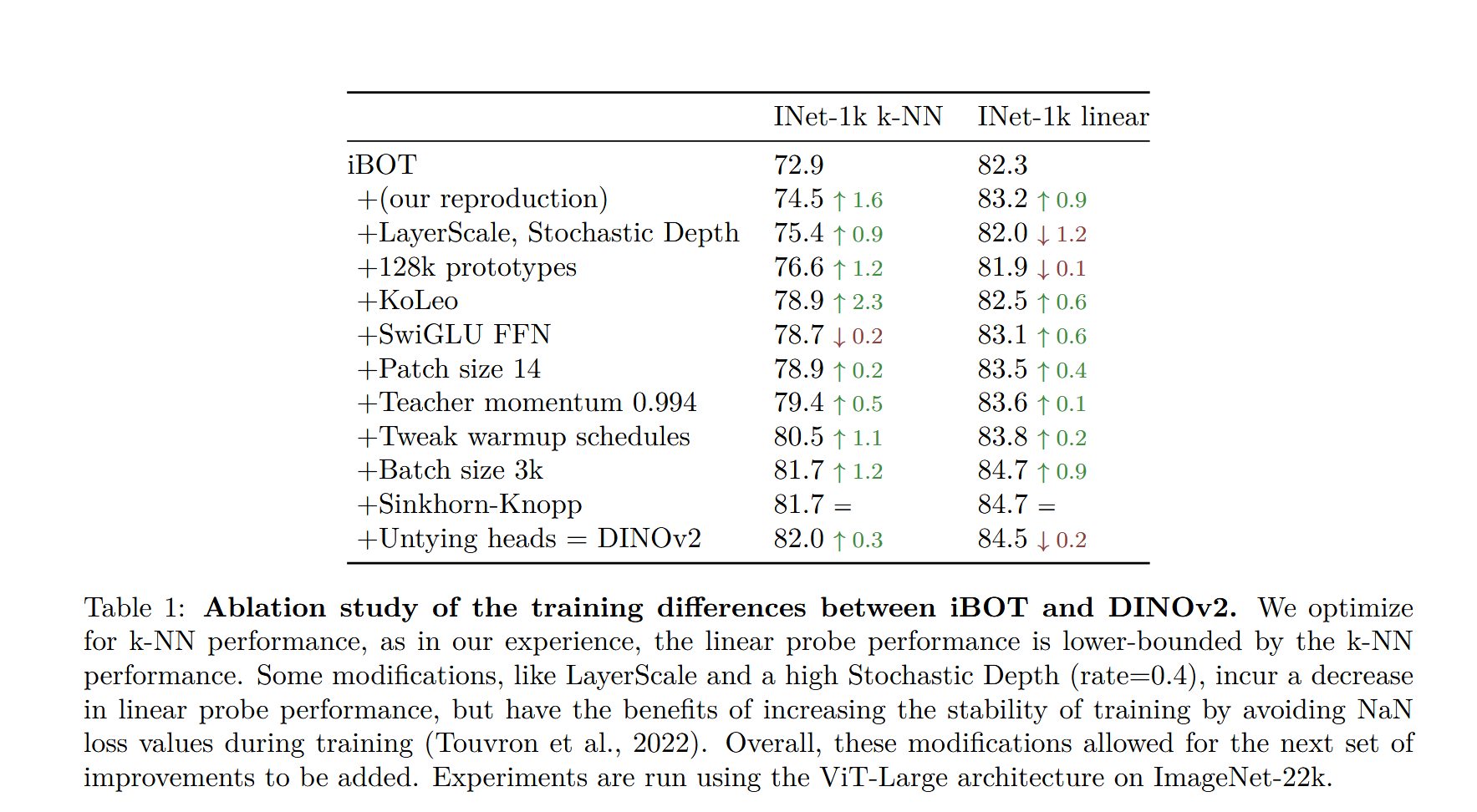
但是我觉得这个消融实验真的是很不直观,为什么是递进式的,而不是通通与原版直接比较?
递进式的比较,在我看来有之后的组件的功能和之前的组件的功能重合导致作用被低估的风险。
然后我觉得我们应该去点一些组件。所以变成下面这张图。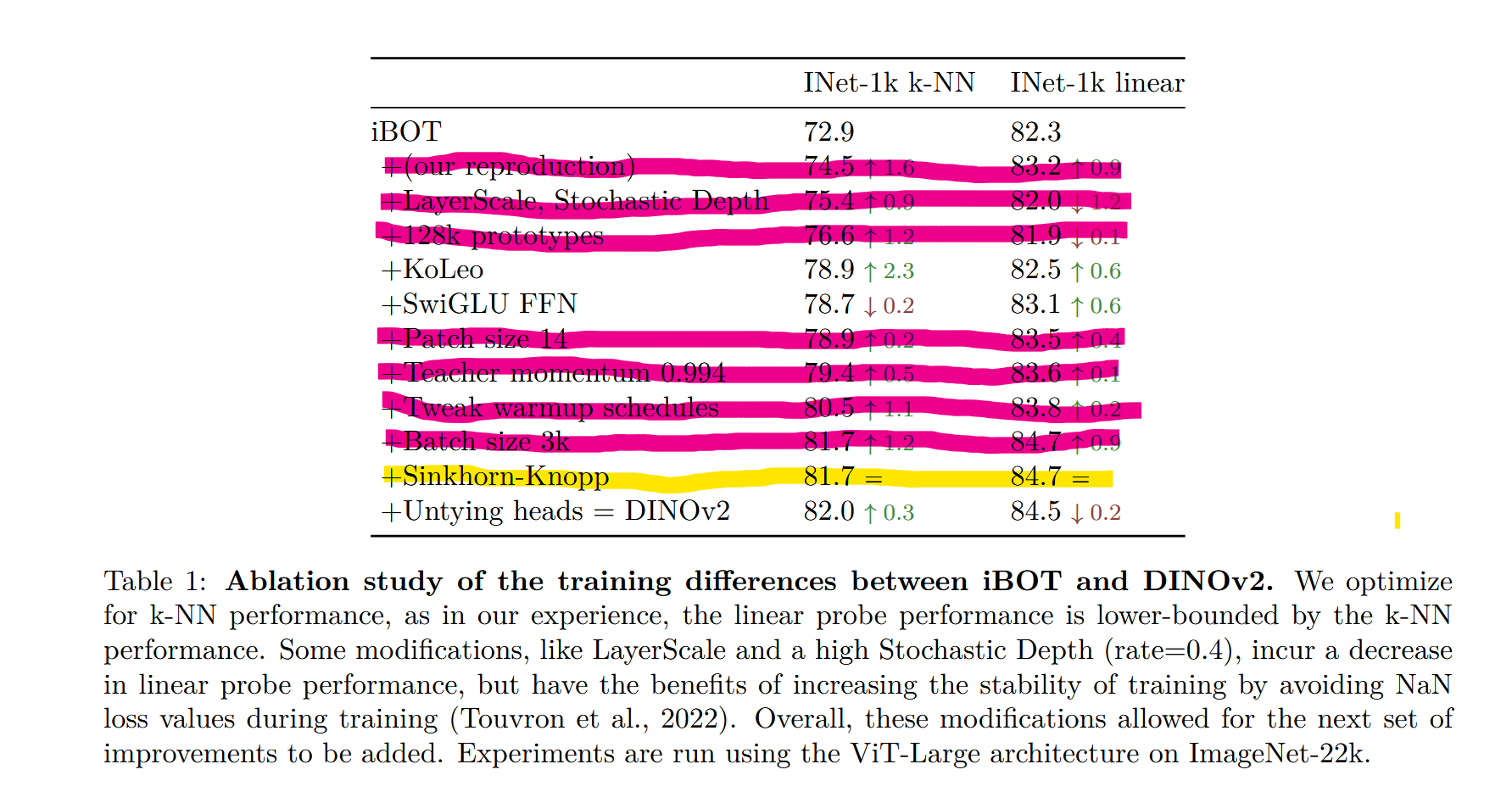
1.重新复现实验的提升我觉得不能算技术。
2.layerscale的提升在我看来属于超参搜索的成果,不算是技术,至于stochastic depth,这里只是提高了效率,不会影响正确率。
3、4、5、6、7.超参搜索。
8.没有变化不讨论
现在只有3个组件需要讨论了,其中untying heads将两个损失头分开 的改动我没把它归为超参搜索,因为它不是只改变数值,但是也没啥好说得,作者自己都说是实验结果更好所以使用。
所以接下来就分别讲一讲这两者。
Koleo正则化
这是一个很容易理解的正则化,公式如下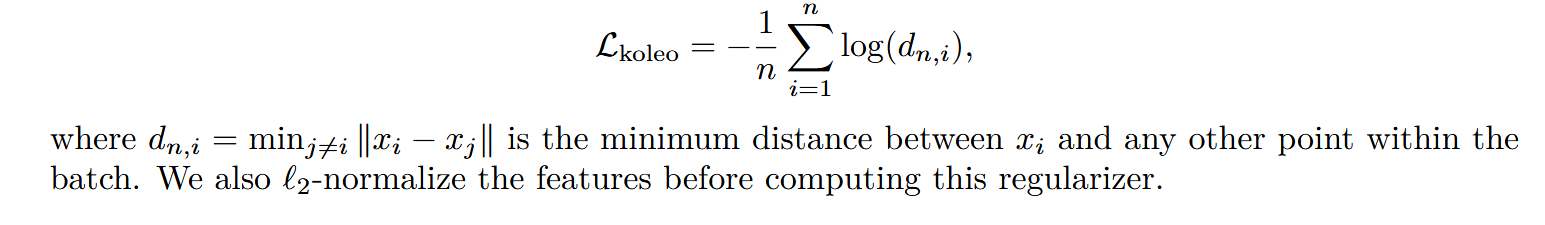
具体来解释一下,其实就是找到每一个输出特征的最近邻(以L1范数为距离度量方式)并对最近邻间的距离去负对数后求平均。
对于这个公式的具体起源这里不做赘述(我也不知道),但是取负对数是很常见的操作,对数具有良好的放大微小差异,缩小大差异的作用。
直观上理解这个公式就是让各个特征之间尽量远离,使得特征空间分布更均匀。
论文中提到在进行Koleo正则化之前号要进行L2正则化,仔细想想这是很有意义的。
因为L2正则化针对的是针对单个特征输出内部不同维度起作用的,它让特征各维度尽量的小。
而Koleo针对的是不同特征之间,让他们尽量远离,他让不同特征均匀分布在特征空间。
共同作用之后特征均匀分布在一个类球面。
swiglu 激活函数
这其实是两种技术的合体,一种是swish激活函数,一种是glu(gated linear units)门控线性单元。
swish激活函数其实本来就有“门控”的意味在里面,公式为:$x*sigmois(\beta x)$,其中β可变。
而glu则是一种神经网络架构方式,公式为:$activate(W_1x+b_1)\odot(W_2+b_2)$总的来说就是类残差的思想,但是从加变成乘了。
提升效率的组件
论文讲了很多的提升训练效率的方法,有很多是很直观的,也有很多是偏硬件优化的,这一部分推荐直接阅读原文。
这里就讲两个,一个是stochastic depth,一个是distillation。
stochastic depth
stochastic depth的思想就是在训练时随机丢弃某个样本的某层网络,还是残差的概念,不同的是因为这里是整层的跳过,如果处理的好的话是可以减少前向时间的。
其实DINO就已经运用了stochastic depth,但是当时是直接根据概率将计算后的结果随机mask掉,如代码所示
1 | def forward(self, x, return_attention=False): |
而DINOV2为了加快运行速度在运算前确定某一层需要丢弃的样本,那么这层这个样本就不参与前向了。
(代码后补)
distillation
整个DINO算法就是自蒸馏框架的,作者在这次训练中尝试了用训练好的ViT-G 架构模型作为教师网络蒸馏出剩余规模的模型。其中有一些小改动,我觉得最值得说的就是作者最后保存的并不是学生网络,而是学生网络训练不同阶段的指数移动平均,这和我们上篇文章的观察是一致的。
作者的实验结果显示蒸馏的模型远好于从0开始训练,这符合直觉,但是竟然在特定任务上超过了教师网络,这让我感到惊讶。
下面给出一张对比图:
泛化性
作者最后做了一个小的实验,那就是在用224的图片预训练完之后用448的图片进行微调,达到了不输完全用448图片训练的效果,这还是很值得一提的。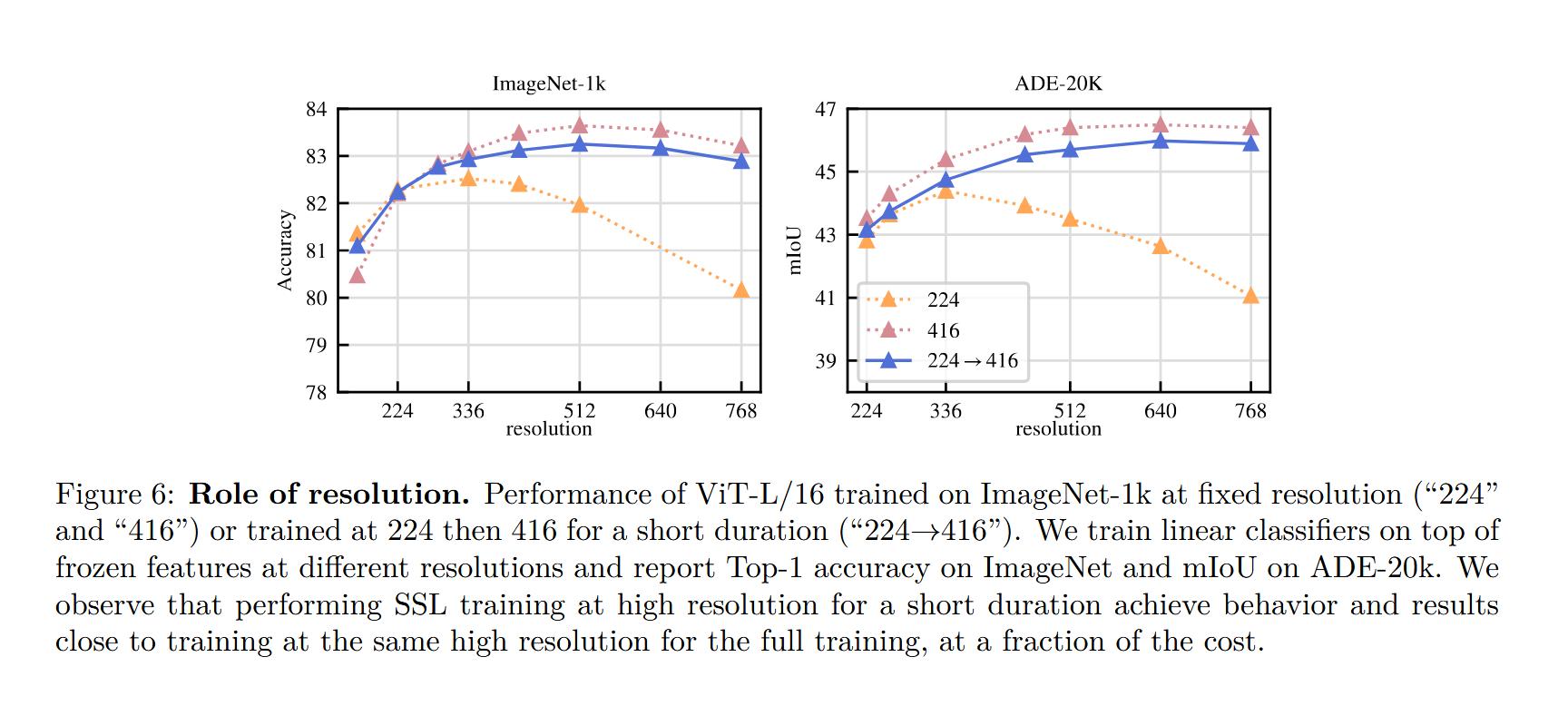
总结
DINOV2可以说是ibot的完善版本,核心框架的改动其实没有,大都是一些零碎的小改动,但是这些小改动如果能够很好的整合到一起感觉也是很费精力和算力的。
DINO系列我觉得最让人有好感的是将全部的训练代码以及模型权重都发了出来,这是很多工作没做到的。