计算机视觉算法 DPT(Vision Transformers for Dense Prediction) 论文解读
前言
正在撰写depth anything的论文,在跑官方实现的时候发现自己在阅读论文的时候漏掉了一个满关键的组件:dpt。
我觉得这个组件值得细致的学习,于是打算先完成dpt的学习以及博客撰写。
先前的博客都是读完论文把东西都弄懂后按照自己理解的重要性撰写的,但是那样实在有点耗时。
这一次尝试一下严格按照 abstract、intro、conclusion、related work、methodology、experiment的顺序阅读论文,并在阅读的过程中直接提炼出认为关键的点进行总结,看看效果咋样。
abstract
概要中作者说它们提出了一个取代卷积网络在稠密预测任务中作为backbone作用的ViT的方法。
稠密预测任务指的是像素级的任务,例如深度估计、语义分割。这一类任务一般要分为encoder和decoder两个阶段,经典的框架就是基于卷积网络的unet,我之前研究的变化检测中就基本都是卷积+unet
作者在这里提出要利用ViT代替卷积作为backbone,将encoder不同阶段的token在decoder阶段通过卷积网络聚合起来。
作者提到了transformer拥有恒定的高分辨率以及全局感受野。
全局感受野很好理解,毕竟transformer对待远近的token的权重都是一样的(学习后可能不一样),不像cnn中像素每次只能和核大小范围的像素进行交互。
恒定的分辨率很好理解,毕竟unet中cnn每个几层都要通过池化层降低分辨率,而vit则是token数目自始至终不变。
但是高分辨率我不是很能理解,因为为了防止计算量爆炸,vit本身就是多个像素作为一个token,像素不高,一直都有vit是远视眼,cnn是近视眼的说法。作者难道提出了新的方法?
作者还提到说它们在很多下游的密集预测任务上取得了很好的表现。
作者发布了推理代码和权重文件,可惜没有训练过程可以参考。
intro
intro部分作者主要介绍了现在的稠密预测任务是怎么做的,有什么问题,他们又是怎么解决问题的,以及具体的实验表现很好云云。总之就是概要的扩写。
作者先是又提起了稠密预测任务的基本架构:encoder和decoder。encoder很重要,被研究的也很多,这是因为一旦你的特征在encoding的过程中损失的话,那就再也不可能恢复了。这其实是很符合直觉的,因为对数据的处理只可能减少信息量,是不可能增加信息量的。
作者然后说了卷积作为encoder时的弊端:分辨率降低,以及人们为此做出了一些努力。但是,作者提到,无论再怎么努力,cnn自身的性质(只能感知周围像素)导致这种弊端不可能完全消除。
最后作者说了自己提出的网络框架dpt,可以解决这个问题,并且实验表现很好。
conclusion
大概就是intro幅度。
但是作者这里提到了很关键的一点,那就是dpt有着transformer 所共有的一个特性,那就是可以充分的利用更大的数据集进行训练,从而达到更好的效果。
related work
我一向是不怎么喜欢related work这个部分的,因为觉得讲的很杂,有用的信息也没多少。
这篇论文也差不多,介绍了cnn和transformer。
但是作者在这里提到了大数据集对于transformer的重要性,可能和接下来的内容有关。
methodology
这篇论文的这部分其实应该是architecture,因为提出的是结构嘛。
整体框架
作者提出的框架其实不难理解,只是有些琐碎,我们先从整体来说,如下图左所示。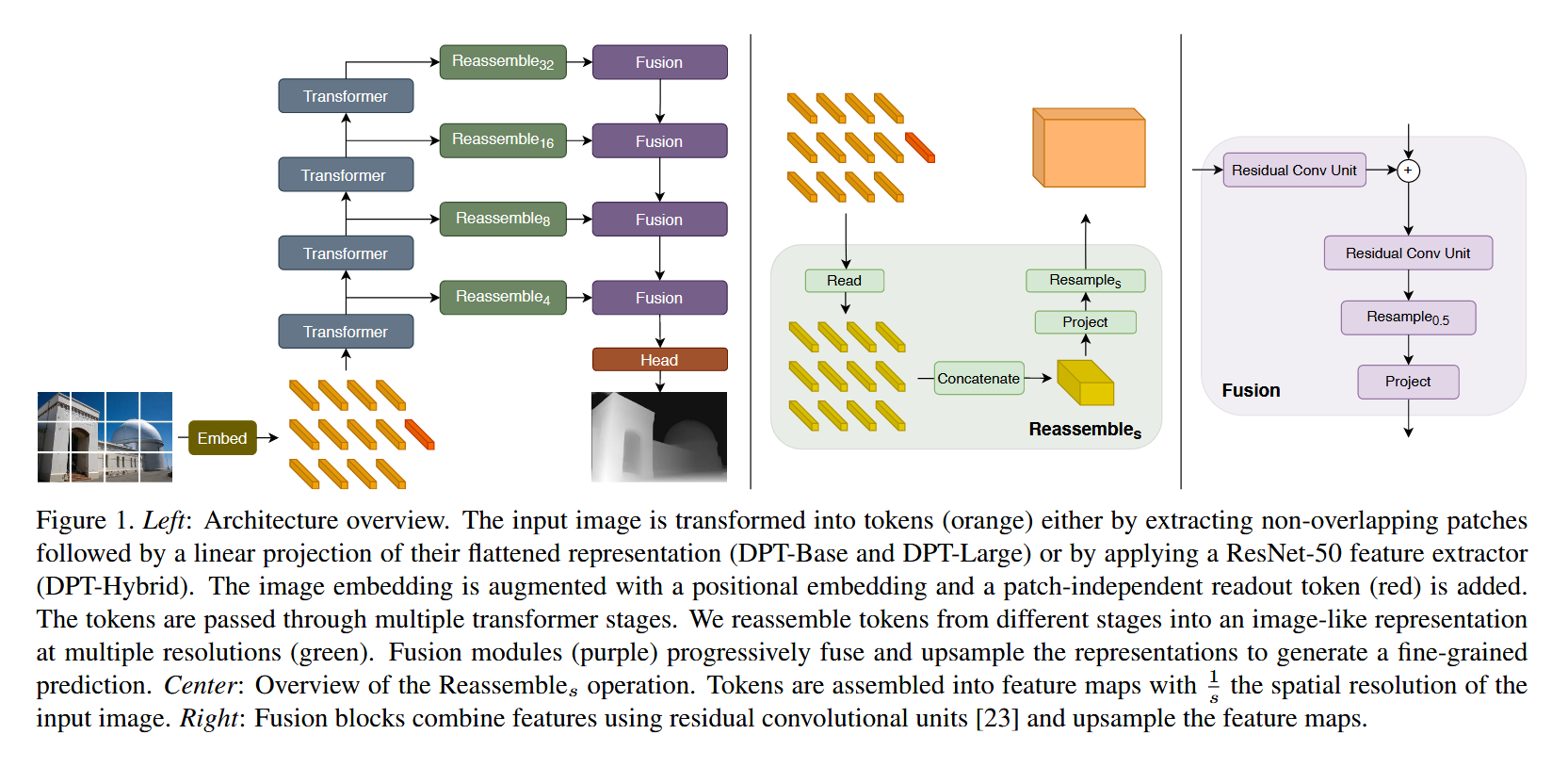
我们将左图放大。
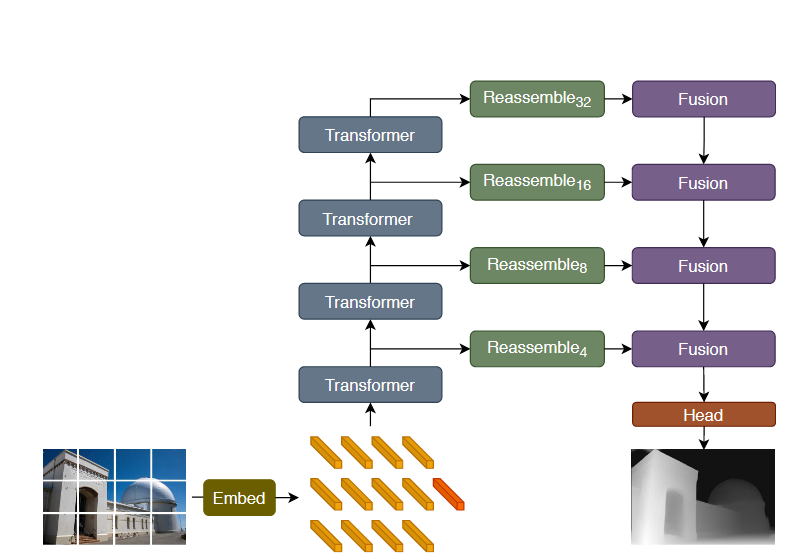
其实就是一个ViT的架构,但是ViT的特定层数的token被保留下来,就跟unet里做的一样。
这些特定层数的token被保留下来后,分别经过reassemble以及fusion两个单元,之后则往后流动。
其实这就是一个unet一样的塔式结构,也就是像素先减小后增大,特征维度先增大后减小。
但是为了适应transformer的token的数量(对应像素)和特征维度都不变的特点,需要reassemble层的特殊处理,所以接下来我们看一看reassemble层。
reassemble层
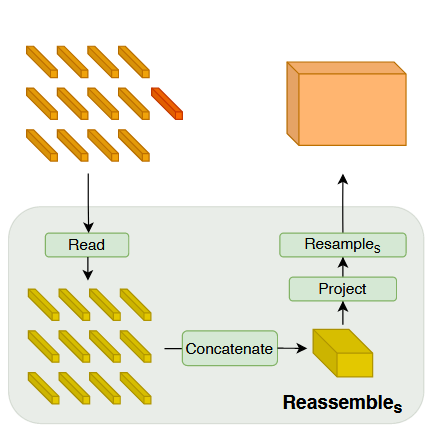
上图就是reassemble层的具体操作,其实我们连公式都不需要,直接看图就能看明白。
读者可能注意到了,为什么这些token中有一个红的?
其实这就是一个额外的和图像信息无关的 token。
有人要问了,要这样一个 特殊的token干吗?
作者解释说这样 的一个 token 可以学习到全局的分布信息(就像cls token 一样)。
在我看来这是有意义的一种操作,因为将全局信息和局部信息分开很明显可以增加局部信息的信息密度,是他们更好表示各自独有的信息。
这其实在强化学习的d3qn中的dueling 中也有体现,那就是将q net的v部分剥离出来,最终提高模型表现。
既然 全局信息被剥离出来了,那么就要在加入回去。
这里就是通过read层完成的,具体的完成方式有很多,可以全连接、元素加、concatenate。
之后我们将一维的token序列按照分开的顺序重新排列成矩阵形式,此时的token就不能叫token了,应该说是像素,tokens组成的就是稠密预测的目标图,只是此时的目标图的高宽、维度全都不对罢了。
所以我们要修改高宽以及特征维度。project修改特征维度,reasample修改高宽。
project是一个1x1的卷积,是很常用的改变特征维度的方法。
reasample则根据最终需要达到的高宽和原始高宽(原始高宽是划分patch时候决定的)谁打谁小决定,进行卷积或者转置卷积。
fusion
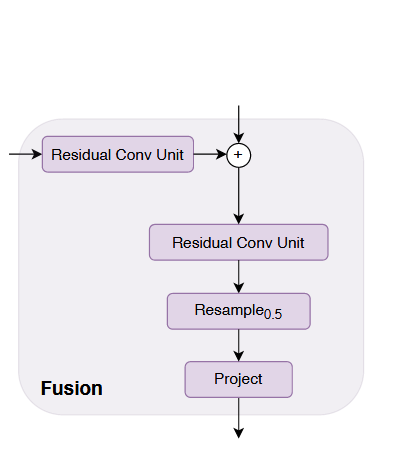
其实fusion层没什么好说的,就是unet的decoder层,完全没有变化,这是因为我们通过reassemble层已经将tokens变成了二维特征图的形式,且高宽、维度都调整到了适合进行decoding的大小。fusion层框架如上图所示。
唯一值得主义的是这个resample的图例有误,但是我们不用在意,只要知道这就是上采样就行了。
generalization
这一节的最后还讲了如何处理不同尺寸的原始图片,其实就是对位置编码进行插值,这个都已经很熟悉了。
(个人觉得这种框架类的论文读再多都不如自己跑一遍,感受一下每一步的具体操作,每一层的具体形状)
experiment
实验部分我觉得是最考验作者写作水平的,也是最考验读者耐心的。
论文作者将实验部分主要分为了三大部分,单目深度估计、语义分割、消融实验。
作者这里讲的很琐碎,连超参是啥都讲了,我觉得这个真的可以放到附录里的。
作者对于单目深度估计以及语义分割的具体训练损失函数等细节反而是略讲了,只是稍微提了几句。因为我对这些了解也不深,很多内容也不是很感兴趣去看引用论文,所以就挑一些我感兴趣的讲一讲。
单目深度估计
对于弹幕深度估计所用的损失函数,作者用了一个超级长句就说完了:
We learn a monocular depth prediction network using a scale- and shift-invariant trimmed loss that operates on an inverse depth representation, together with the gradient-matching loss
我们一个一个来看损失函数的构成。
首先就是对齐的目标,是inverse depth representation,也就是深度图的倒数,这可以称之为视差图,这个取倒数的操作在直觉上是很有意义的,因为对于人类的感知来说,深度从0.1-0.2的感知变化远大于深度从10.1-10.2的感知变化,所以相应的模型应该对近处的变化更加敏感。
再来看 scale and shift invariant,也就是尺度和平移不变性(这里的平移不是指事物在图中的坐标平移了,而是整体的尺度图的值平移了)。
这是通过线性仿射实现的,具体来说就是通过将预测的逆深度图进行一个统一的线性映射后与真实的逆深度图比较来实现。
注意,这里的线性映射只在训练时用到,具体来说就是通过求$min{(az_{pred}+b-z_{gt})}^2$的解析闭合解a和b,然后求损失。
再说trimmed loss ,也就是损失裁剪,也就是对误差相对于真实你深度图的比例大于阈值的像素点不计算损失。这很符合直觉,我们可以用课程学习的角度来理解。
损失过大可以理解为很难预测,我们就先不学习难预测的。等到模型增强,曾经很大的损失变小,我们就可以学习了。
最后来说gradient-matching,也就是梯度匹配,这个操作具体来说就是对于输出的逆深度图进行差分,对真实的逆深度图也进行差分,然后将差分图求mse loss。这种操作有个好处,就是可以强化模型对于边缘的感知。因为这个损失对于单个像素的逆深度图的绝对误差完全不考虑,只考虑像素间差值的绝对误差,将优化的目标简化了。
作者在弹幕深度估计部分还做了一个小小的消融实验,如下图所示。
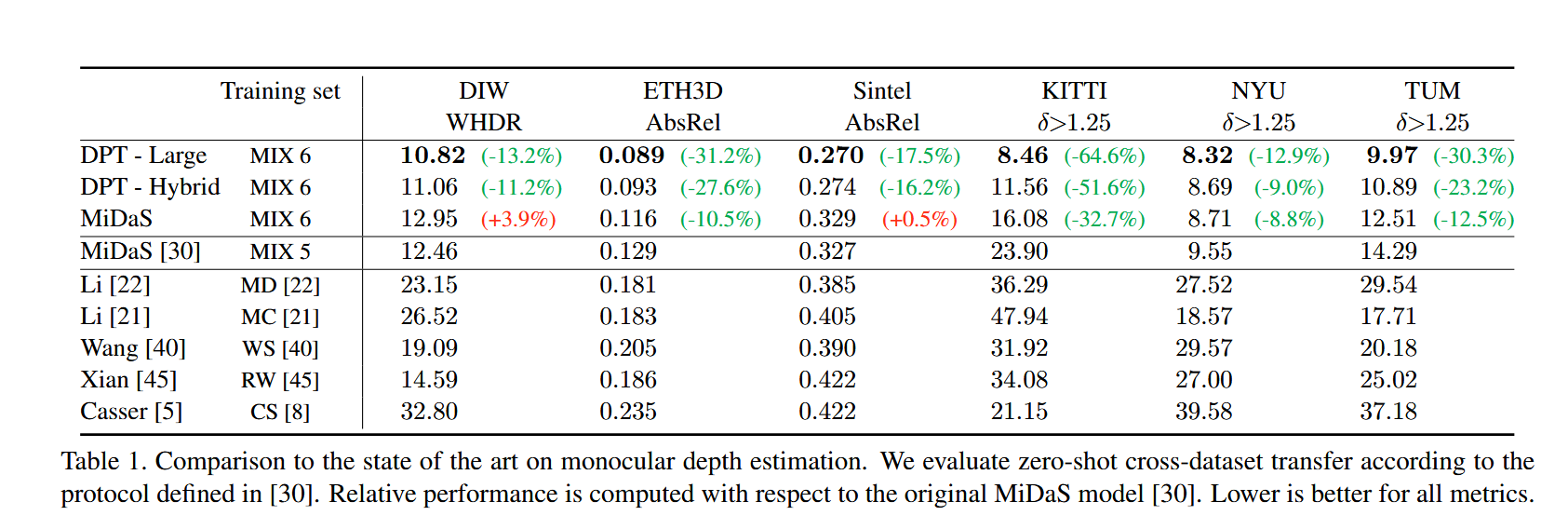
具体来说就是作者证明了我们的数据集有用,我们单独框架有用,我们的数据集加上我们的框架更有用。很简单但是足够了。
作者还提到了它们在绝对深度图的数据集上是怎么测试的。
因为前文提到过,作者对于损失函数是进行了仿射变换的操作的,这导致模型完全不在乎绝对输出了,只要相对关系是对的,仿射变换后就能让损失函数很低。
但是这也有一个问题,那就是模型只能输出相对逆深度图了,它没法是输出绝对你深度图。
所以作者想到一个办法,在训练集上计算每次仿射变换的a和b,取了均值后用到测试集上。
当然作者不仅这样做,还在训练集上训练了,当然我觉得训练是不太需要的,或者说不训练只取ab更有说服性。
语义分割
我对作者说的很多操作都不太懂,作者给了引文,但是考虑到引文是五年前的,并且我计划阅读sam系列模型,所以就先不进行语义分割部分的学习。这一部分就空着了。
消融实验
skip Connection
大致就是决定从哪几层抽取tokens用于最后decoder层,最终结论就是靠前层和靠后层都要有,感觉没啥值得说的,就是纯粹的超参搜索。
readout token
实验了之前提到的对于readout token的不同处理方式,最终发现mlp的处理只比不利用readout token好一点,其他处理则是弱于不利用readout token,也是有点好笑。但是话又说回来了,在训练时保持这样的一个特殊token绝对是对下游任务的多样性有好处的。
backbones
结论是预训练的encoder好于重新训练的encoder。
inference resolution
逐渐增大测试图像的尺寸,发现用ViT作为backbone有一个很大的好处就是面对尺寸远大于训练图像的测试图像时,表现下降的更少。
这是因为cnn在面对图像时需要足够的深度逐渐增加感受野,尺寸太大可能深度就不够了。
而ViT则是从一开始就有着全局的感受野。
这其实是因为ViT的位置编码的泛化性较好,相信更换更好的位置编码是提升图像尺寸泛化性的关键。
inference time
没啥好说的,我甚至感觉结论都没啥好说的。
总结
这篇论文提出了一个类似unet的架构,用ViT替代了encoder,在ViT的tokens输入达到decoder之前进行了一系列的处理使其可以不用改变decoder架构。
后补
自己跑了一下官方的实现。
一开始是很惊喜的,因为官方的实现并没有很多的依赖要安装,只有一些通用的包,这样起码不用担心不同依赖造成的版本冲突了。
但是自己真的跑了才觉得这个实现不太适合学习。作者将各个功能都拆分的很细,很简单的功能要调用好几个类/函数来实现,博主就被绕晕过好几次。函数/类的复用性确实很重要,但是代码的可读性也是很重要的。一篇工作看懂的人多了,在它之上做工作的人才会多。
我没有用过swin T,但是在机器学习课上听过基本思想,当时的一句话我现在仍记忆犹新:因为这个网络架构太复杂了,所以虽然性能比ViT好,在swinT之上的工作很少。
自己跑了之后还有一点体会,那就是感觉这篇工作仍然是unet的范畴,所谓的将encoder替换为了transformer的说法我感觉有点取巧,毕竟你的reassemble不就是cnn吗,这也是encoder的一部分。