计算机视觉算法 depth anything 论文解读
前言
DINOV2有很多的下游应用领域,有很多工作就是将DINOV2当作预训练的backbone使用的,都取得了比较好的效果。
去年我在学习遥感图像处理的时候,就用过其中的一个工作:depth anything v2(GitHub),当时只是拿来即用,没有仔细的研究过其中细节。
最近正好有时间,就把这部分内容重新整理一下。
(同样,对于mde领域我没有太多了解,难免有错漏之处)
depth anything所用的网络架构没有什么创新,还是dpt那一套(参考我上一篇博客:计算机视觉算法 DPT(Vision Transformers for Dense Prediction) 论文解读),但是训练过程却是新意十足,所以我们就围绕训练过程进行讲述。
如何利用未标记样本
最近看的工作基本都是通过大量的未标记样本显著的提升了原有的sota结果,这篇工作也不例外。
当然了,除了大量的未标记样本,标记样本的数量也大大提升,主打的就是一个力大砖飞。
论文作者利用DINOV2作为预训练的backbone,应用于dpt的框架下,用大量的标记样本训练了一个教师网络,之后则利用这个教师网络对未标记样本进行标记。
然后再利用所有的样本(标记样本,被教师网络标记的未标记样本)训练一个学生网络。
奇怪的是,最后的结果现实学生网络的能力并没有超过教师网络,也就是学生网络并没有从未标记样本中学到额外的知识。
作者对这种现象进行了直觉上的解释:教师网络和学生网络有着完全相同的架构以及预训练权重,很容易学到相同的表示。并且标记样本数量已经更多了,未标记样本很难提供额外的信息。
其实我对作者的第一次实验是有疑惑的,作者为什么会期望学生网络的能力超过教师网络呢?在我看来,DINO那样的自蒸馏方式训练的核心是学生网络和教师网络的任务目标不一样,也就是说学生网络面对的任务远远难于教师网络,但同时我们用教师网络简单任务的表现要求学生网络,那么最终学生网络的能力会提升到超过教师网络。(当然了,在dino里通过对教师网络进行移动指数平均使教师网络一直强于学生网络)
所以说一个朴素的观念就是更难的任务带来更好的表现,但是前提是你有足够多的训练样本,训练样本稀缺的问题就是自监督来解决。
作者之后的实验也是这个观念的体现,作者简单的将学生网络的输入进行了cutmix数据增强,同时保持教师网络输入不变,就大大提升了学生网络的表现,实验对比如下图所示。
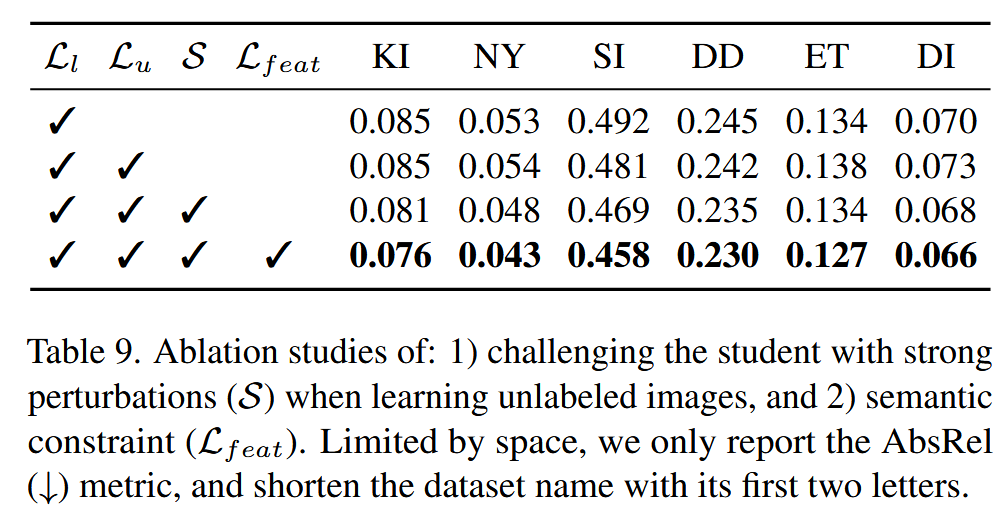
cutmix
我简单的介绍一下cutmix。
随机选取两个未标记样本。
通过下面的式子,计算出一个矩形框的大小。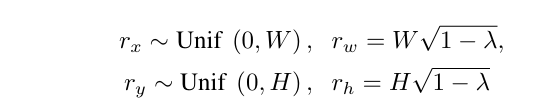
这个矩形框可以也就是掩码区域M。
然后进行如下操作。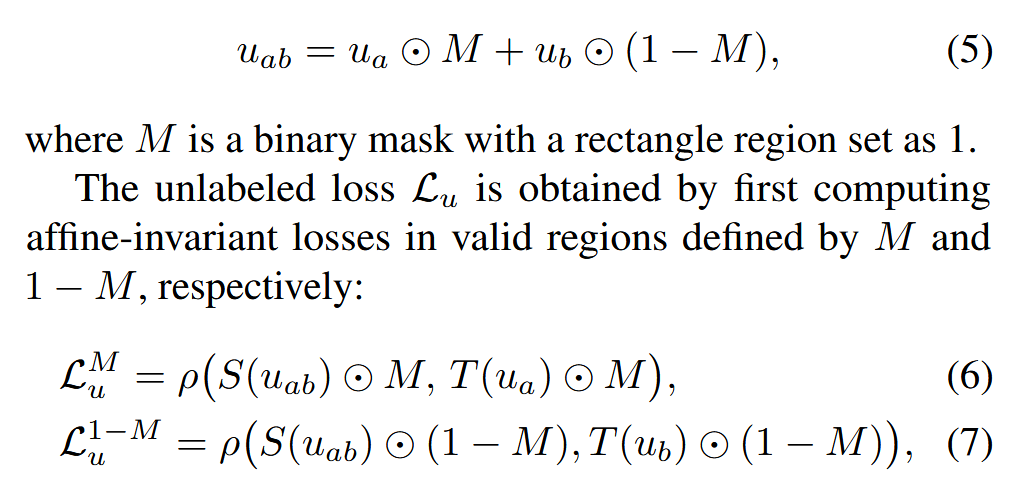
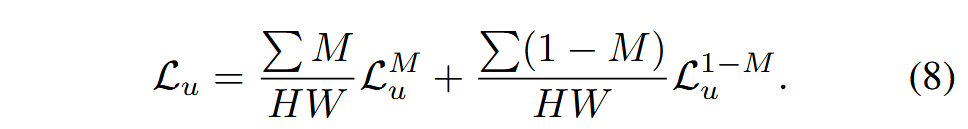
也就是说从两个未标记样本各自选中一部分,对于未选中的部分置零,分别计算损失,然后加权。
值得注意的是,和dino一样,作者只对学生网络进行了一系列的数据增强,这是为了保证学生网络的任务难于教师网络。
我这里比较奇怪的是为什么要强调是只对未标记样本进行操作?不过论文作者并没对这方面做消融实验。
总的来说我觉得cutmix这个方法的具体做法不重要,重要的是得有cutmix这类数据增强的方法。
语义对齐
论文作者尝试通过语义分割这个辅助任务来提升mde的表现。
具体来说论文作者将dpt框架模型的decoder增加一个,也就是两个任务分别有自己的decoder,但是共用encoder。然后对于未标记样本通过语义分割模型打上伪标签,让模型同时拥有两个损失函数。
最终作者并没有成功,作者总结是语义分割图的语义标签是离散的,包含的语义信息太少了,给不了什么监督信号,尤其是我们的深度估计效果已经很好的情况下。
我个人倒是还觉得部分原因是模型对语义损失的学习集中在了语义分割对应的decoder上,深度估计任务很难从中受益。
作者之后做出了改进,不直接用语义分割图作为监督信号的,直接拿dinov2的特征输出作为监督信号。
这有两点好处,首先就是因为特征输出是连续的,信息量够大,其次是并没有额外的decoder,监督信号能够完全的增益深度估计任务。
具体公式如下: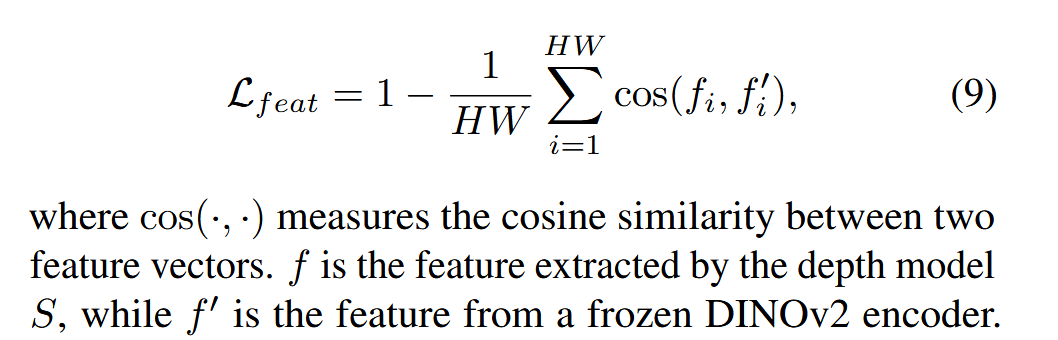
消融实验也可以看出,这确实是一个有用的措施。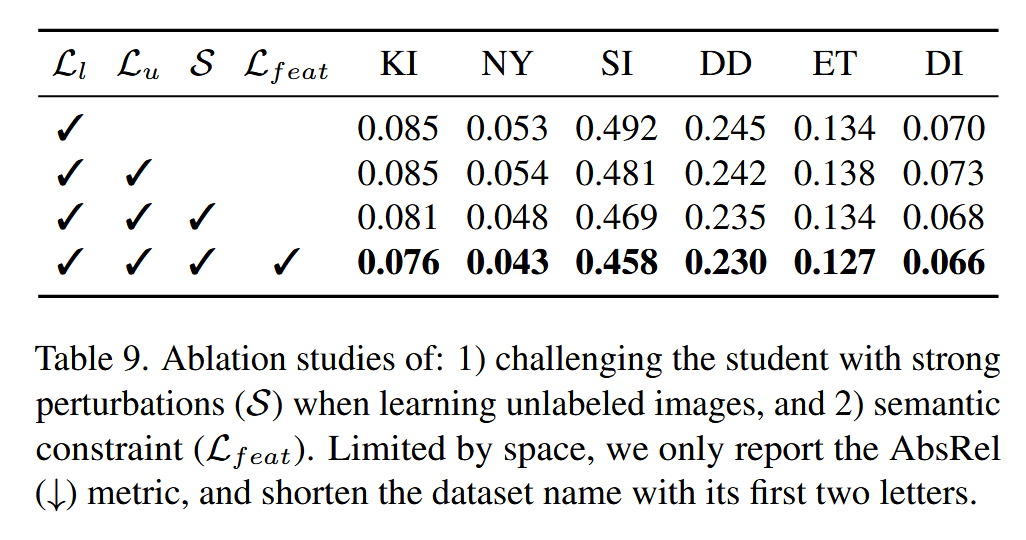
论文作者这里还做了一个额外的操作,就是如果两个pixel(这里的pixel我觉得只是一个类比,实际是token)的相似度太好了,那就不把它计入最终损失函数,这来源于一个观察,语义特征总是倾向于对事物的不同部分分配相同的特征,而深度估计则不是这样,事物的不同部分的深度是根据特定情况而定的。实验证明了这一点。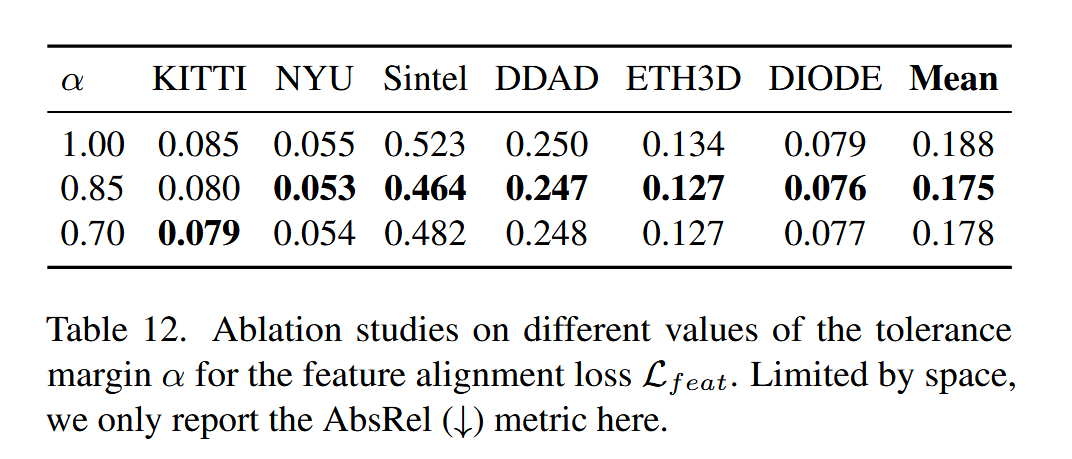
所以强制让encoder对齐dinov2是不合理的,因为这样不就和直接不更新encoder没区别了。
部署细节
论文作者也提到了很多部署时候的实验细节,我这里简单总结一下。
首先就是对encoder和decoder使用不同的学习率,encoder的学习率是decoder的学习率的1/10.
这很符合直觉,因为encoder是预训练的,而decoder则是随机初始化的,如果不这样操作的话,模型在训练的一开始就会因为decoder造成的巨大损失形成的梯度极大改变encoder的权重,导致预训练的效果难以体现。
其次就是语义特征的对齐,论文作者也研究了将其应用到有标记样本的效果,结果和不应用效果差不多。论文解释说这是因为有标记样本本身的标签质量就是很高的,如果引入额外的损失,可能会让高质量的监督信号被稀释。实验如下图。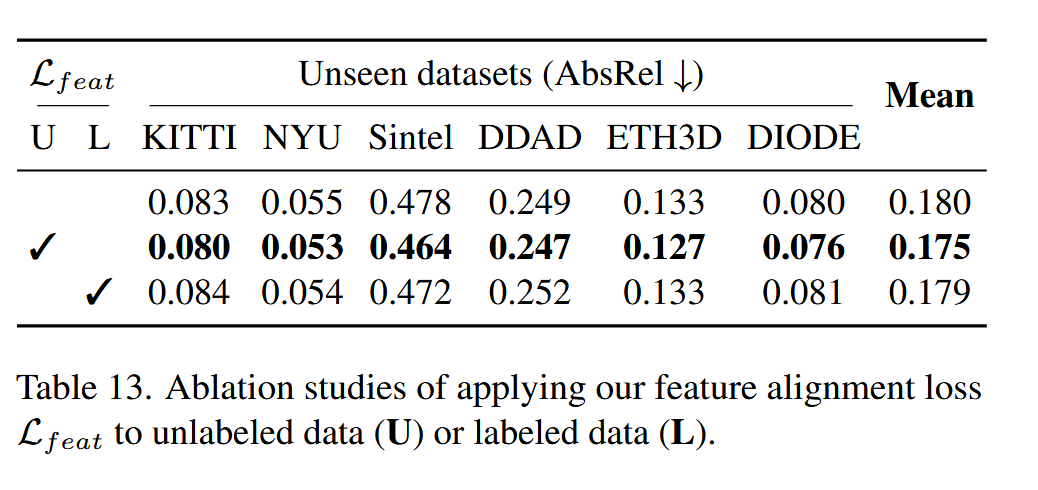
我个人倒是有点好奇,之前的数据增强就没有对有标记样本进行,这里的消融实验真的有严格控制变量吗?
总结
depth anything 提出了一种高效利用未标记样本的训练方式,同时利用dinov2的特征表示作为额外的监督信号,在不改动原有框架的情况下大大提升了模型的效果。
depth anything这篇文章整体看下来还是很舒服的,作者没有使用很多特别花哨的技巧,但是效果的提升很显著,而且消融实验也很完善。
最让我佩服的是根据论文所说,这篇工作一开始的实验方向都不成功,是多次修改后才变成论文中的这样,这种毅力和执行力令人佩服。
关于数据增强对半监督学习框架重要性的讨论(后补)
对于自监督或者说半监督的范式中的无标签样本的利用其实我一直是有疑惑的。
疑惑的点在于为什么教师网络在面对无标签样本时的表现很差,但是学生网络经过训练后在无标签样本上的表现反而能超过教师网络呢?
我之前的理解是对学生网络的输入进行了数据增强导致了学生网络的目标任务远远难于教师网络,但同时我们用教师网络简单任务的表现要求学生网络,那么最终学生网络的能力会提升到超过教师网络。
现在我总结了一下自己的看法,做出如下叙述:
半监督的核心要点都是
判别式模型 利用有标签样本/无标签样本的数据分布信息+利用有标签样本提供的数据到标签的映射关系。
利用有标签样本提供的数据到标签的映射信息可以理解,就是以标签作为需要拟合的目标进行训练。
利用有标签样本的数据分布信息要怎么理解呢?
在我看来,如果是纯粹的mlp,或者是单个像素对应一个token的transformer的模型是学不到有标签样本的数据分布的。
因为判别式模型本质是学习一个从数据到标签的映射,只是单纯在死记硬背罢了,这样的模型是不具备泛化性的。
或者我们可以这样说:泛化性的存在==模型学习到了数据分布信息
而引入cnn的inductive bias、引入transformer的位置编码等一系列操作却是能够将模型引导回到对“输入结构”的建模,反过来学习到了数据的分布性。
当然这些操作都是依托判别式任务的框架进行的,模型是在学习数据到标签的映射关系的过程中顺带学习了原始数据的分布。
但是,无标签样本的分布信息可以学习吗?
生成式任务例如扩散模型,自回归模型。这些任务的目标就是对数据分布的拟合,并没有标签的概念,所以可以直接学习数据分布信息。
判别式任务却是不行,因为没有标签,我们的训练框架都不能用了。
而 教师学生组合则是为无标签样本保证了不变的判别式框架(伪标签),同时依托于这个框架展开对数据分布的学习。
怎么理解呢?
教师学生组合 保证了整个任务的框架还是判别式的,学生训练的目标是数据到标签的映射关系而不是数据的分布,那么我们就能在这个框架下进行对数据分布的学习。
那么为什么这么多半监督的方法单独使用效果都很差,必须要配合数据增强呢?
在我看来,那就是就算我们能通过模型本身的架构(cnn的内在偏置、transformer的位置编码)学习到数据分布,但是我们训练的目标,也就是需要拟合的数据到标签的映射信息是错误的,这会导致我们的数据到标签的映射关系实际上是越学越差了。(这是因为伪标签是教师网络产生的)
所以一者变好,一者变差,最终的结果就是学生网络的表现和教师网络相当,并没有提升。
而数据增强是怎么解决这个问题的呢?
首先我们来看一下数据增强是怎么学习数据到标签的映射关系的。
学生网络的输入进行数据增强,破坏了数据的原有分布,
但是教师网络的输入没有进行数据增强,所以伪标签中包含了数据原有分布的信息。
学生网络拟合目标为数据到标签的映射关系,相当于潜在的要求学生网络做两件事:
1.从被破坏的数据A恢复原有数据B(学习数据的原有分布,生成式任务)
2.通过恢复的原有数据B得到伪标签C(学习标签的分布,判别式任务)
所以数据增强可以促进学生网络学习伪数据A到伪标签C的映射关系
但是数据增强又是为甚么可以 不恶化数据到标签的映射关系,从而达到整体效果的提升的呢?
这是因为数据增强让学生网络的训练目标有了细微的改变。
它让学生网络的训练目标由B到C变为了A到C
学习的是伪数据到伪标签的映射关系
虽然模型学习伪数据到伪标签的映射关系可能还是会恶化数据到标签的映射关系,但是恶化程度肯定是更轻了。
于此同时模型还在学习数据的分布信息,所以整体的表现会提升。