计算机视觉算法 depth anything v2 论文解读
前言
总算学到 depth anything v2了。去年在遥感领域科研(并非科研)的时候尝试的方向就是结合深度图进行变化检测。
因为只进行了简单的模型拼接效果很差,可以说是只带来了副作用。
现在想来当时的具体操作上的问题暂且不谈,最大的问题是发生在宏观观念上面的。
我的目的是解决变化检测中 建筑物相关的检测正确率,
假设是模型无法区别建筑物和其他后景、植物。
解决方法是融合深度图作为监督增加模型对于建筑的语义理解。
开始工作前我以mde rs cd 为关键词在wos上检索了一下有没有相关工作。
但是今年开学时发现mde在遥感领域有它自己的名词,而事实是深度图帮助变化检测的工作已经存在了。
对一个领域没有广泛而深入的研究之前不应该开始自己的研究。
扯得有点远了,还是说回depth anything v2吧。
这篇工作的模型框架相较于depth anything没有一点变化,甚至你在实践的时候都不需要把v2的仓库clone下来,直接下载权重放在v1的文件夹中改一下路径就可以用了。
论文作者保持了他一贯的作风,不考虑fancy的技巧,而是从训练方法论的层面反思v1的训练有什么问题,可以怎么改进。
我是很赞同这种工作方式的,就像我在drl的交流群里看到人们经常讨论的那样,每一个trick都是人们的一种先验,drl领域的trick格外的多,这么多的trick导致模型的性能极端依赖于特定任务的调参、trick选择。这根本就不是一个健康的研究领域应该有的情况。
论文作者的行文很流畅,排布很合理,所以我大体上就按照他的顺序来总结了。
整体思路
论文开篇对比了当前mde领域的两种技术路线,也就是生成式模型和判别式模型。
具体的对比表格如下:
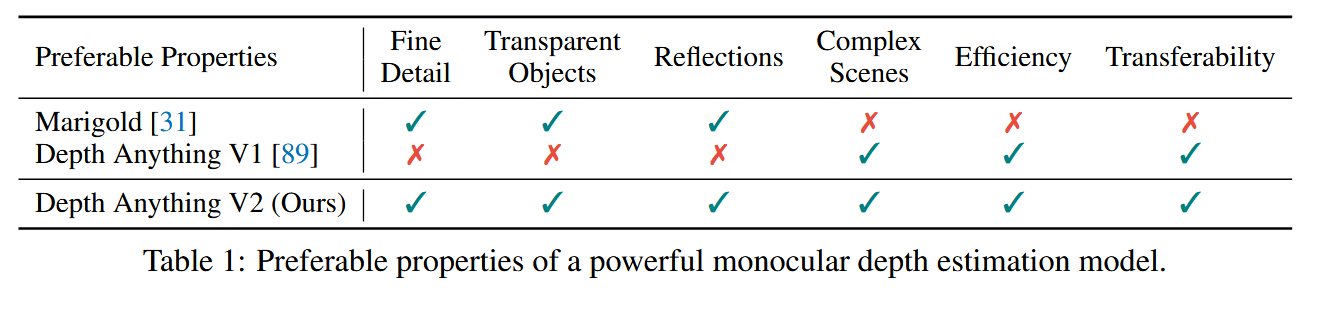
从表中可以看到生成式模型的代表marigold有着更好的细节处理,对于透明物体以及反射情况的表现更好。
判别式模型的代表depth anything则能面对更复杂的情况,推理效率更高,泛化性更好。
那么这种差异的来源是生成式模型和判别式模型的范式不同吗?
作者研究后发现,除了效率问题是模型范式不同造成的,其他的差别都是训练范式不同造成的。
具体来说就是marigold只用了生成数据进行训练,生成数据精度高,所以marigold对细节的处理更好。
depth anything则是先在labelled数据上训练教师网络,再在很多的unlabelled数据上训练学生网络,所以能面对复杂情况,泛化性更好。
那么怎么同时有以上两种优势呢。
作者提出的方法就是将训练教师网络的人工标注数据完全替换成生成数据。
这是很符合直觉的。
其实思路是很直接的,但是作者还是一步一步的分析了为什么人工标注的数据不好,为什么生成数据好,生成数据有什么缺点,为什么论文里使用的教师-学生网络的训练范式能解决这种缺点。。。。
我感觉论文在这一块是有点罗嗦了,作者自己在附录中的数据来源的分析我感觉就是论文概要。
为什么我说作者在这里有点罗嗦了呢,因为其实关于半监督范式提升泛化性的说明在v1中已经说过了,真的没有必要再大谈特谈。
但是这里可能也是为了论文的完整性。
损失函数
v2的损失函数是什么呢?就是dpt论文的损失函数。
相较于v1就是多了一个梯度匹配的损失函数,具体的实现细节在dpt论文中已经讲过了,这里就不多说了。
计算机视觉算法 DPT(Vision Transformers for Dense Prediction) 论文解读
我这里比较想讲一讲作者为什么在v2中要使用梯度匹配损失。
首先我们要知道的是梯度匹配损失是在强调学习像素间的变化,所以加了梯度匹配损失是可以加强模型对于细节的处理的,下面的图证明了这个观点。
(虽然更多考虑梯度匹配损失边缘就越锋利,但是这样的话就越会忽略像素间的绝对深度差,所以作者选择了一个适中的系数)
但是作者在v1中为什么不适用梯度匹配损失呢?是没想到吗?
其实是因为v1的实验结果表明不加效果更好,而v2的实验结果表明加了效果更好。
作者解释说是因为v1中的人工标注数据太粗糙了,你学细节学到的也是错的,学了也白学。
这种对于损失函数的抉择可以看出作者对于实验的细节把控。
当然了作者还做了很多的消融实验,有些实验的结果是该因素影响不大。
但我想要是没有广泛的实验的话,也找不到潜藏在一众无关痛痒的因素中的决定性因素,并据此总结出具有泛用性的规律。
评测数据集
作者在论文中还提出了一个新的数据集,这是因为之前的数据集都是人工标注的,所以精度很差,这会导致模型在数据集的表现无法完全反应模型能力。
作者通过稀疏标注解决这个问题。
之前的数据集精度差是由设备决定的,不是作者所能解决的问题。
但是作者通过稀疏标注使得标注精度可以通过人工检查不断提升,最终得到精度接近于百分之百的数据集。
具体来说就是作者将收集到的原始数据通过sam模型生成掩码,然后随机选择两个掩码,获得它们对应的关键像素。
然后利用四个sota模型对这两个关键像素进行排序,谁在谁的前面,这个就是标注信息。
一旦模型有分歧,就由人工进行标注。
整个流程走完后每个样本还会有两个标注员在三检查,确保数据集精度够高。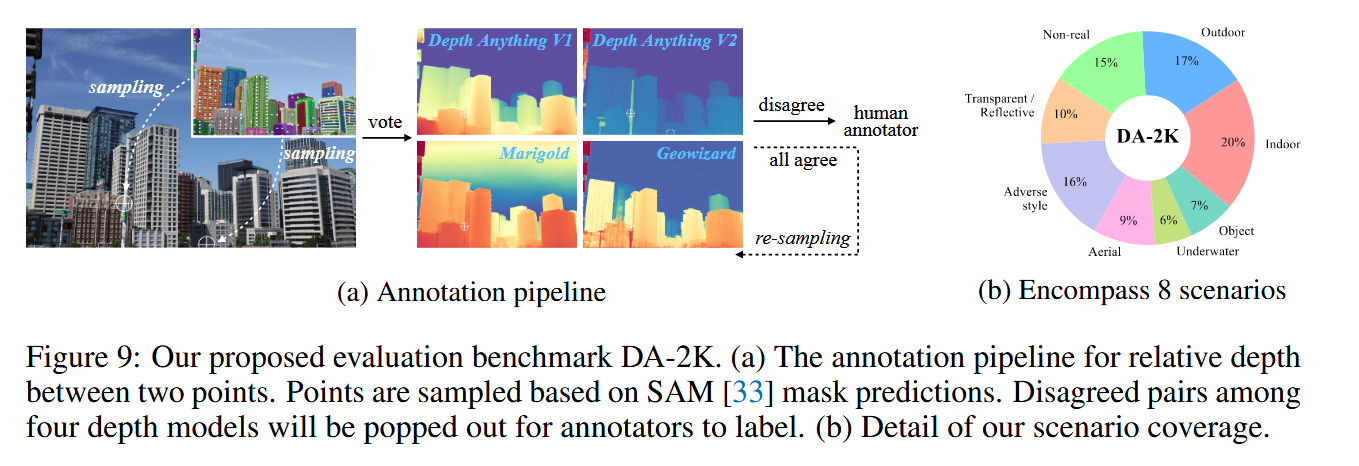
数据集的来源也是尽量覆盖了mde的应用场景,作者将想到的应用场景交给gpt4,让它生成一系列相关的关键词,作者再通过这些关键词从网络上检索相关的图片信息。
具体的应用场景样本间的比例如下: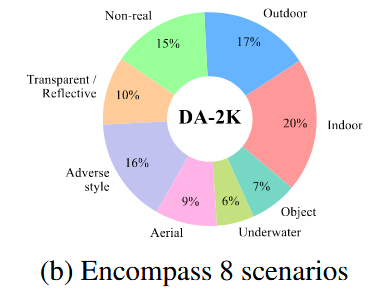
工作不足
作者谈到了两点当前工作的不足,
一是模型训练、推理消耗太大了,所以要考虑未来在效率上多做功夫。我觉得这点不是那么的关键,想要效率的提升得是基本架构的大刀阔斧的改革,在mde领域的研究可能很难搞明白怎么做到这点。
二是生成数据的数量以及覆盖领域太少了,未来要收集更多这种类型的数据。我觉得这点倒是大有可为,并没有第一点那么大的困难。
总结
depth anything v2通过将教师网络的训练数据从人工标注的数据集替换为生成数据显著提升了模型的精度,同时通过让学生网络在广泛的未标注数据中进行学习显著提升了模型的泛化性。
在不使用花哨技巧的前提下,通过转变训练范式,大大提升了模型效果。
整篇论文结构清晰,围绕着核心观点进行讨论,消融实验也做得很充分,强烈推荐大家阅读原文。